

Written by Jared Hillam
 Snowflake shocked the market by becoming the most valuable software IPO in history. But what is Snowflake? Often when IPO candidates get exposure to the market they start abstracting their message to simplify what they represent to the masses. So it can at times be difficult to really understand the value statement. The intent of this white paper is to piece apart what Snowflake is without getting too abstract, yet not drowning the reader in complexity.
Snowflake shocked the market by becoming the most valuable software IPO in history. But what is Snowflake? Often when IPO candidates get exposure to the market they start abstracting their message to simplify what they represent to the masses. So it can at times be difficult to really understand the value statement. The intent of this white paper is to piece apart what Snowflake is without getting too abstract, yet not drowning the reader in complexity.
The Problem to be Solved
Every company has data spread all over. The ability to turn that data into information presents significant barriers to organizations being able to actually "observe" their business. For companies that have actually executed automation to turn data into information,  they know that the process is FAR from automatic. Data Engineers and Architects roll their eyes at some of the buzzword-driven perceptions of a pixie dust process that turns data into information. The truth is that it's really hard work, and at times it feels like you're using sticks and stones to build a skyscraper. So having better tools is REALLY earth-shattering in this discipline. The irony is that there's no shortage of tools in these categories; Databases, Integration Tools, Orchestration Tools, and Analytics tools abound. This is the backdrop of the market Snowflake was entering into when it was founded.
they know that the process is FAR from automatic. Data Engineers and Architects roll their eyes at some of the buzzword-driven perceptions of a pixie dust process that turns data into information. The truth is that it's really hard work, and at times it feels like you're using sticks and stones to build a skyscraper. So having better tools is REALLY earth-shattering in this discipline. The irony is that there's no shortage of tools in these categories; Databases, Integration Tools, Orchestration Tools, and Analytics tools abound. This is the backdrop of the market Snowflake was entering into when it was founded.
It's a Database
First, Snowflake is a database. That ham-handed description might make some Snowflake aficionados cringe, as many people have a very narrow interpretation of what a database is. In the end, Snowflake offers a connection for querying data. But unlike many databases it isn't designed to do EVERYTHING. Snowflake is designed for bulk data ingestion and bulk data delivery. So if you're looking for Snowflake to run your transaction system that reads and writes singular records, the answer is no. On the other hand if you're asking Snowflake to cough up millions of records for analytics, the answer is YES!
It's a Cheap Storage, Database
The cost of storing data in Snowflake is about as low as you'll ever find. To explain why, there's first some credit due to AWS, Azure, and Google Cloud. The foundation of the Snowflake's storage layer sits on top of their blob storage solutions.  That might sound strange, but it turns out to be an excellent location to allocate storage. It's cheap, unassuming, secure, file-based, highly programmable, and virtually unlimited in size. One other feature that makes blob storage so compelling is that it is immutable, meaning the data doesn't go away or update in place. As records come, they just get added, and added, and added for any record whether it's new or changed. This might seem to be a negative for a database that provides analytics, but Snowflake turned that into a massive advantage.
That might sound strange, but it turns out to be an excellent location to allocate storage. It's cheap, unassuming, secure, file-based, highly programmable, and virtually unlimited in size. One other feature that makes blob storage so compelling is that it is immutable, meaning the data doesn't go away or update in place. As records come, they just get added, and added, and added for any record whether it's new or changed. This might seem to be a negative for a database that provides analytics, but Snowflake turned that into a massive advantage.
It's a Time Traveling, Cheap Storage, Database
To interface with this immutable storage, Snowflake created a system of pointers which ensured the user was looking at the correct records with the latest updates. If a record received an update, this pointer layer would simply flag the updated record, and it would stop pointing to the older record. What this also meant is that Snowflake users could actually travel through time by awakening older snapshots of pointers. If a developer accidentally dropped a table they could just undrop it and the table would rise from the dead.
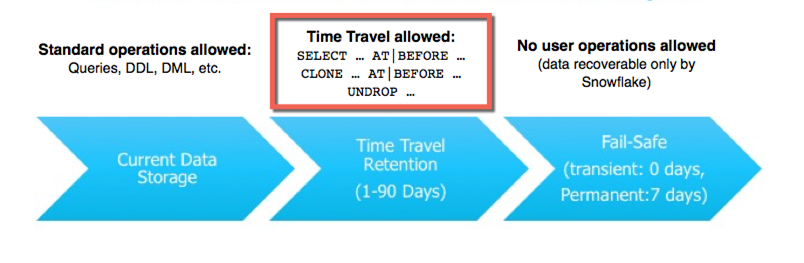
It's a Cloneable, Time Traveling, Cheap Storage, Database
Now that we have these pointers pointing to the immutable storage layer, what keeps us from copying a snapshot of those pointers and just calling it another database connection? If we did clone these pointers would it double the data footprint? No, because all we're doing is cloning the pointers and not the underlying storage layer. The official name of this feature is a Zero Copy Clone, and it completely changes the life cycle of how you manage data. 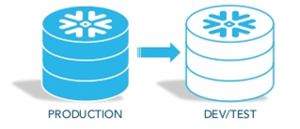 If you pay virtually no penalty for making a copy of a "database," how would that change your Development, Test, and Production operations? Imagine being able to instantly copy an entire Data Warehouse to run an experiment on a whim. Previously impossible.
If you pay virtually no penalty for making a copy of a "database," how would that change your Development, Test, and Production operations? Imagine being able to instantly copy an entire Data Warehouse to run an experiment on a whim. Previously impossible.
It's a Really Fast, Cloneable, Time Traveling, Cheap Storage, Database
Early on, the speed at which Snowflake returned data from a query is what immediately distinguished it from competitors. For example, take a look at the query duration after a 2018 migration Intricity conducted from AWS Redshift to Snowflake. This specific use case had 0 optimizations made to the queries. The difference in query speed was shocking.

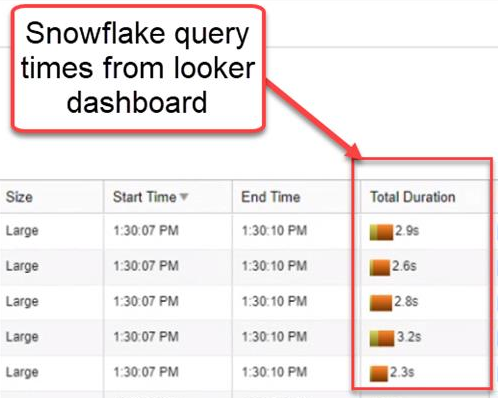
That's not to say that there weren't situations where a previous database couldn't be faster than Snowflake. For example, if the database engineers had specially tuned a query to be faster by hand, they often could get it to outperform Snowflake. However, for the broad spectrum of queries Snowflake was remarkably faster.
Today, Snowflake has vastly opened up the ability to tune queries and competitors have narrowed many performance gaps related to raw query speed.
Under the hood, Snowflake uses a system for organizing the data it receives into "bins" which it calls micro-partitions. Think of these as bins of data which allow for less scanning of every record to find something (making queries really fast). 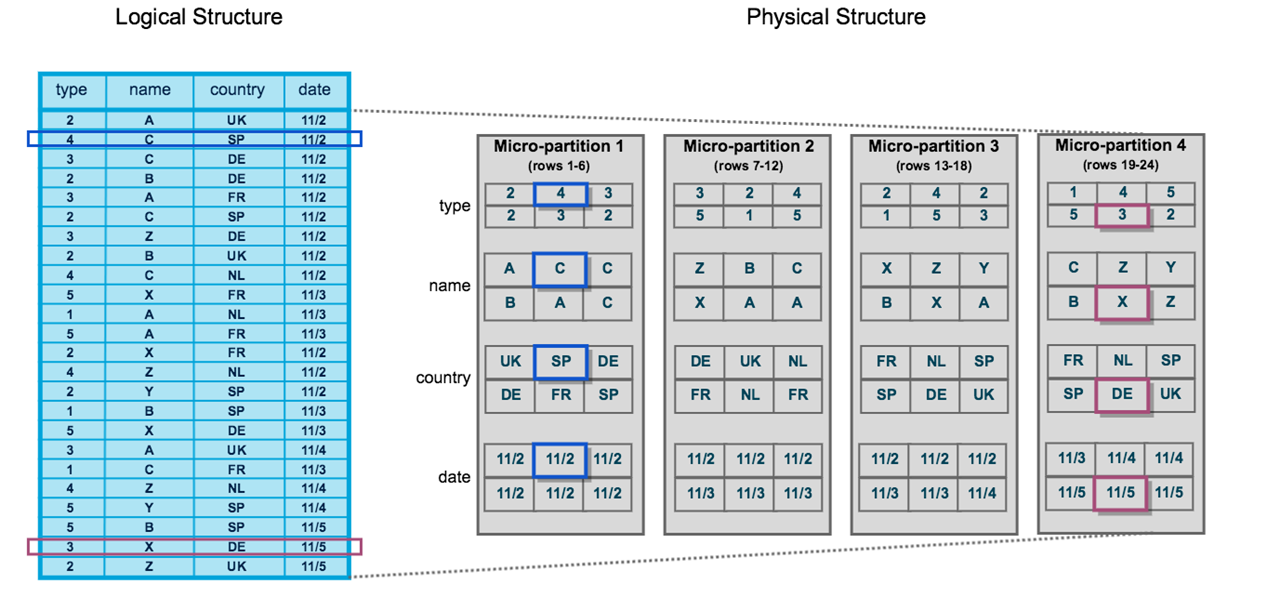 On top of that, Snowflake automatically organizes the micro-partitions to optimize queries for time ranges and other common indexing requirements. These all happen behind the scenes.
On top of that, Snowflake automatically organizes the micro-partitions to optimize queries for time ranges and other common indexing requirements. These all happen behind the scenes.
Part of the appeal of this auto-indexing is the ability to "cheat the Piper" a little. In most solutions you really "pay the Piper" before you can actually make a query a reality. This is because the performance is so slow that it pushes the users to engineer a more efficient query. Snowflake is slower with these kinds of data sets as well, but not nearly as slow as most. The combination of micro-partitions and auto-indexing allow us to cheat the Piper and still make such queries a reality. That doesn't mean that we throw good engineering practices out the window, it just means that the prospect of having Data Science teams interacting with raw data is doable when queries come back with a semi-respectable duration.
It's a Hyper-Elastic, Really Fast, Cloneable, Time Traveling, Cheap Storage, Database
To this day (Sep 29, 2020), database vendors, including the ones that are owned by the "big cloud platforms", struggle to mimic Snowflake's ability to scale without a fuss.
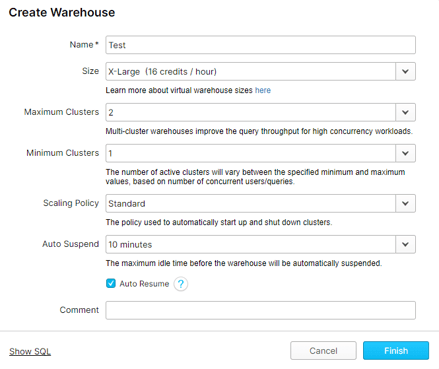 The "pointers" that we talked about earlier act as a ready executor for queries. When a Snowflake customer wants to execute a query they select a compute scaling policy which Snowflake calls "Warehouses." These scaling policies allow organizations to build fine grain rules for how aggressively to scale and to what size. These can be sized for a data loading job or a group of Executive Dashboards, and everything in the middle. Additionally, the Warehouses can be summoned in an in
The "pointers" that we talked about earlier act as a ready executor for queries. When a Snowflake customer wants to execute a query they select a compute scaling policy which Snowflake calls "Warehouses." These scaling policies allow organizations to build fine grain rules for how aggressively to scale and to what size. These can be sized for a data loading job or a group of Executive Dashboards, and everything in the middle. Additionally, the Warehouses can be summoned in an in line SQL Query to trigger the Warehouse and shut it off when done. You read that right, "shut off." Snowflake's compute layer is designed to turn off so its clients don't have to pay for idle time.
line SQL Query to trigger the Warehouse and shut it off when done. You read that right, "shut off." Snowflake's compute layer is designed to turn off so its clients don't have to pay for idle time.
This may trigger you to ask, "What if I have another user fire a query? Won't that take a long time if we have to wait to spin up a compute cluster?" The answer is no. Snowflake addresses this by keeping a hot-pool of compute which is managed by a machine learning-based system to forecast the compute demand. The result is instantly available compute on demand and at your desired level of aggressiveness. From an end user perspective, this means a very consistent and fast query time that doesn't get hung up with competing queries.
It's a Semi-Structure Ready, Hyper-Elastic, Really Fast, Cloneable, Time Traveling, Cheap Storage, Database
Semi-structured data went from being a side dish to the main course for many organizations. This was basically the trend as organizations went from most of the data being on premise to most of the data being sourced from SaaS applications in the cloud. The cost of delivering analytics on semi-structured data was always a pain for integration teams as it required them to break the structure into querable tables.
 Snowflake created a table type called a Variant table which automatically parses out semi-structured data into query ready tables. The variant structure supports a wide verity of file types including JSON, Avro, ORC, Parquet, or XML.
Snowflake created a table type called a Variant table which automatically parses out semi-structured data into query ready tables. The variant structure supports a wide verity of file types including JSON, Avro, ORC, Parquet, or XML.
One of the compelling points about this is the ability to mix structured and semi-structured queries directly from a Variant table. The amount of time saved here cannot be understated.
It's a Multi-Cloud, Semi-Structure Ready, Hyper-Elastic, Really Fast, Cloneable, Time Traveling, Cheap Storage, Database
Snowflake is a cloud only solution. They don't claim to compete with on-premise requirements. If an organization isn't ready for that, they aren't ready for Snowflake. For organizations that are adopting the cloud, there's pretty much 3 options that represent a vast majority of the market: AWS, Azure, and GCP. Snowflake started on AWS, then came Azure in 2018, and GCP in 2019. In 2020, it has rolled out a feature that allows for seamless replication between the 3 cloud vendors. In effect, if you own Snowflake you can have your data backed up not only within your cloud vendor of choice but between clouds. The interface from one cloud vendor to another is literally unnoticeable. So if you know Snowflake on Azure, you know it on GCP and AWS.

It's a Shareable, Multi-Cloud, Semi-Structure Ready, Hyper-Elastic, Really Fast, Cloneable, Time Traveling, Cheap Storage, Database
Pre-Snowflake sharing data between two companies was NOT an easy task. Here's what the process looked like:
- Company Sharing the Data
- Segment the data for what is to be shared. If this is automated it was programmed into an ETL tool.
- Export the segmented data to a file.
- Zip the file

- Put the file on an FTP Server
- Provide the client a secure login to the FTP Server
- Company Receiving the Data
- Download the File
- Unpack the file
- Set up an ETL process to conform the file to the company's database structure
- Query the database
- Repeat for a refresh
The biggest issue with this old process is that it was never really SOLVED; it required multiple technologies for both the sender and receiver. Whenever a refresh was required, the whole process had to reoccur on both ends.
With Snowflake already being in the cloud, it seemed to be half way there to simplifying this process. So in 2016 it began pitching the vision of sharing data. Today Data Sharing is a highly scalable and repeatable process:
- Company Sharing Data
- Create a secured view of data for the organization you would like to share your data with
- Provide Credentials
- Company Receiving the Data
- Log in
- Query using standard SQL
- Data is LIVE, no repetition
One overarching configuration that needs to be decided is how to bill the compute. Does the bill come to your organization or does it go to the organization consuming the data you're sharing? Once in place, users can consume at their leisure. Additionally, providers of data can focus on efforts to make the data more logically useful then dealing with the blocking and tackling process of moving data around.
There's more to this, of course. Organizations will need to plan out access controls. This is something Intricity has extensive experience in facilitating. However, both the old and new process bare this same requirement.
It's a Shareable, Multi-Cloud, Semi-Structure Ready, Hyper-Elastic, Really Fast, Cloneable, Time Traveling, Cheap Storage, Database with a Readily Available Data Marketplace
Naturally if you can share data so readily, it makes sense to turn that data into a marketplace. To that end, Snowflake has created a Data Marketplace where data providers can sell their data to organizations looking for enrichment. So if you need weather data, why go through the hassle of uploading stagnant files? Instead, just subscribe to a share of weather data from a reputable provider on the marketplace. This concept is making the process of enriching data sets less of a one-off event and more of a permanent improvement.
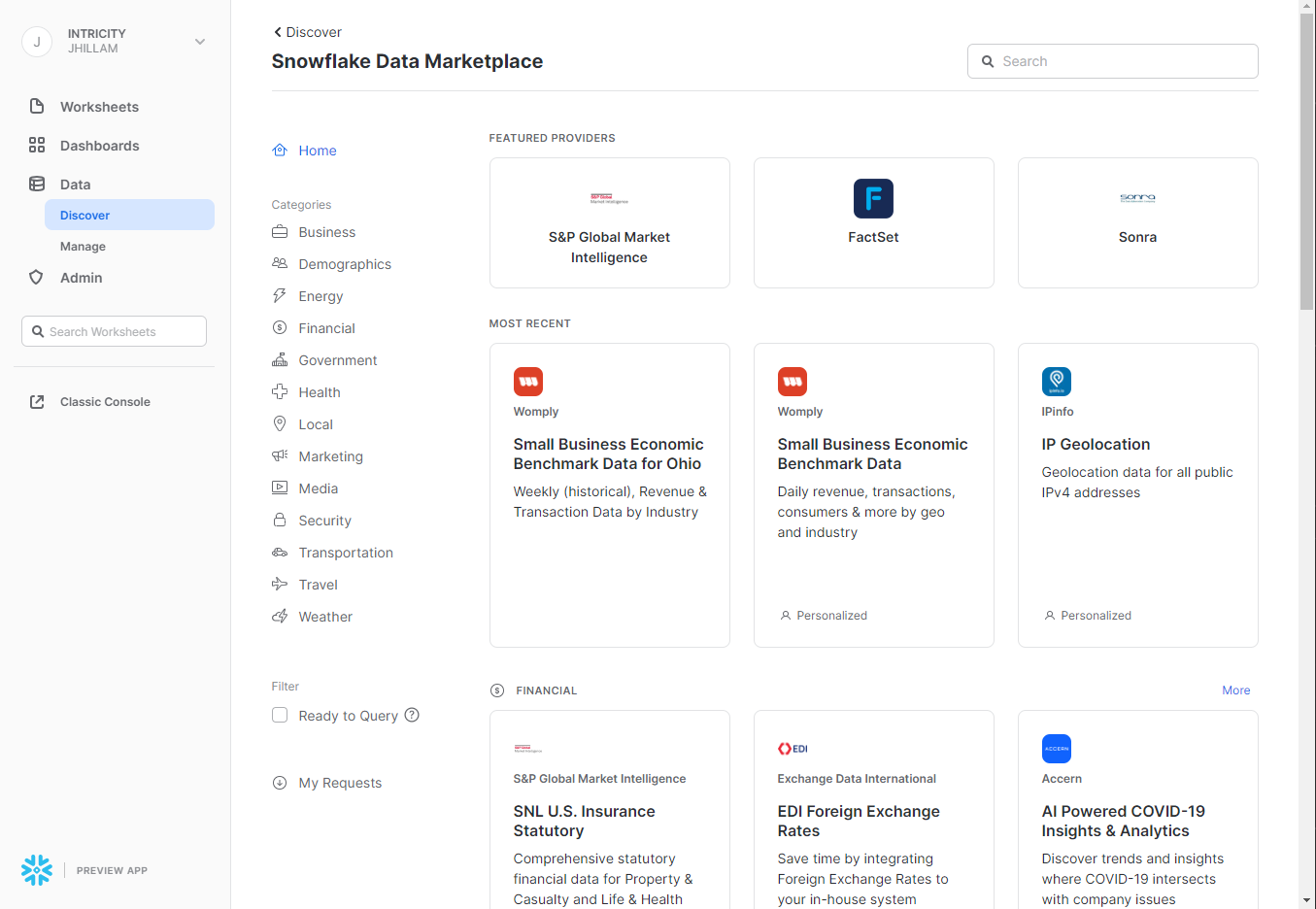
Maybe That's Why
Having better tooling that isn't just a buzzword-act is REALLY earth-shattering in this data management space. There's no shortage of tools in these categories; Databases, Integration Tools, Orchestration Tools, and Analytics tools abound. So when Snowflake solved so many of these nasty challenges at once it really was (and is) transformational.
So the next time somebody asks you "What is Snowflake?" you can tell them it's a Shareable, Multi-Cloud, Semi-Structure Ready, Hyper-Elastic, Really Fast, Cloneable, Time Traveling, Cheap Storage Database with a readily available Data Marketplace.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
