

Written by Jared Hillam
One of the biggest trends in the data management market over the past 2 years has been the migration of legacy systems to cloud-native solutions. This is not to be confused with the early migrations to the cloud (2012-2016) which were often just trading a data center lease for a AWS "rental" agreement. 
 These early migrations were mostly just moving the location of the existing systems. So instead of owning the data center, they would keep the same operating systems and simply "lift and shift" the datacenter to be managed by AWS, then later Azure and Google. However, this model was more of a method of offsetting the physical security of the servers to another entity and the cost savings for doing that was often in question. While organizations were doing this, the cloud vendors were sharpening their base offerings. As time went on, the native innovations in the cloud were outpacing the on-premise, or firewall-driven, solutions. While the difference in features and functions were slight in the beginning, they began to be compelling enough to entice organizations to convert. However, doing such a code conversion was not simply just a no-brainer migration, rather it required a translation of the existing code base to a new compliant language to the target technology. In the case of databases, this could mean converting all the SQL to be native to the target platform of choice; in the case of an ETL tool, it could mean converting all the legacy metadata (often in XML) to the target ETL technology's metadata language. This is the state of the market today with over a billion dollars worth of code conversions in the balance.
These early migrations were mostly just moving the location of the existing systems. So instead of owning the data center, they would keep the same operating systems and simply "lift and shift" the datacenter to be managed by AWS, then later Azure and Google. However, this model was more of a method of offsetting the physical security of the servers to another entity and the cost savings for doing that was often in question. While organizations were doing this, the cloud vendors were sharpening their base offerings. As time went on, the native innovations in the cloud were outpacing the on-premise, or firewall-driven, solutions. While the difference in features and functions were slight in the beginning, they began to be compelling enough to entice organizations to convert. However, doing such a code conversion was not simply just a no-brainer migration, rather it required a translation of the existing code base to a new compliant language to the target technology. In the case of databases, this could mean converting all the SQL to be native to the target platform of choice; in the case of an ETL tool, it could mean converting all the legacy metadata (often in XML) to the target ETL technology's metadata language. This is the state of the market today with over a billion dollars worth of code conversions in the balance.
Many organizations have been conducting projects to convert code within the last year or so. Intricity got started conducting code conversions by hand from Redshift to Snowflake in 2017. The need for automation was painfully obvious. Now that 5 years have passed, there are many lessons learned which Intricity takes from client to client and here are the Top 10.
#10 Conducting the Code Conversion by Hand

With labor costs abroad so low in certain countries, a bruit-force code conversion is often a consideration many organization evaluate. The sizing appraisal for these efforts is almost impossible to measure accurately mostly because the body of code now has a body of people. The performance of the code conversion leans heavily on process controls to manage that body of people and what suffers is the consistency of the converted code. To state the obvious, one person converting a Stored Procedure may take a different approach as another person converting a stored procedure.
When conversion of code happens manually, the typical approach is to order the conversion based on what is easiest for the organization to test. Naturally in a Data Warehouse, organizations will want to convert code by subject matter. Thus when hand converting, the System Integrator will often reconvert the same code multiple times as they traverse each subject matter. However, this code will likely get reconverted by different people each time. So the patterns that simplify your deployment are completely lost in the end.
Conducting code conversions by hand is not recommended for anything over a 20 job pilot. This is one of those situations where cheaper doesn't mean you get the same thing for less.
#9 Not Using Your Automation for Repetitive Errors

Perhaps it goes without saying, but automation exists for these kinds of code conversion efforts. However these tools are not magic. They are pattern-based engines like BladeBridge that see coding scenarios and provide analogous code in the target platform. Every migration is going to have oddities in the code that make it unique. Often during a conversion project, it can be tempting to meet a deadline by making manual adjustments to the code rather than making updates to the pattern engine. Organizations that do this often pay the price later when this pattern reemerges. Thus one of the steps during a conversion that is critical is to have a full analysis of the code patterns so the repetition of those patterns is fully understood. Organizations that do follow Sprints for running projects may need to be a little more practical to ensure they aren't shooting themselves in the foot with a "quick fix" to meet a self-imposed short-term deadline.
#8 Assuming You Can Ignore the Data Integration Layer During Your Database Conversion
 Snowflake made a big splash in the database market. AWS, Google, and Azure are doing the same, all pressing hard to get organizations to migrate their legacy MPP/Data Lake deployments to their respective cloud solutions. Thus the database is getting the megaphone during such conversion efforts. However what often does not get discussed is how the database is receiving its data. Surprisingly this gets consistently brushed aside as a topic of discussion.
Snowflake made a big splash in the database market. AWS, Google, and Azure are doing the same, all pressing hard to get organizations to migrate their legacy MPP/Data Lake deployments to their respective cloud solutions. Thus the database is getting the megaphone during such conversion efforts. However what often does not get discussed is how the database is receiving its data. Surprisingly this gets consistently brushed aside as a topic of discussion.  What is often discovered after months of deliberation about the database is that the conversion complexity doesn't live in the database. Rather it lives in the ETL/ELT layer. To Data Architects, this revelation is not a surprise as the integration tool is where Data Warehouses stuff all their complexity. Thus it's important to treat your entire data-to-information pipeline as a subject to be converted. There are cases where there is no integration layer, but rather the data is loaded directly into the data warehouse and all the crunching happens natively in the MPP database. For these such conversions, it's OK to consider integration a database function. However, that represents a very narrow market and most of them have already converted their code. Most organizations have some ETL tool being used that either needs to be repointed or replaced.
What is often discovered after months of deliberation about the database is that the conversion complexity doesn't live in the database. Rather it lives in the ETL/ELT layer. To Data Architects, this revelation is not a surprise as the integration tool is where Data Warehouses stuff all their complexity. Thus it's important to treat your entire data-to-information pipeline as a subject to be converted. There are cases where there is no integration layer, but rather the data is loaded directly into the data warehouse and all the crunching happens natively in the MPP database. For these such conversions, it's OK to consider integration a database function. However, that represents a very narrow market and most of them have already converted their code. Most organizations have some ETL tool being used that either needs to be repointed or replaced.
#7 Not Fully Defining the Future State Architecture Ahead of the Code Conversion Project
As mentioned earlier, the features and functions of these new cloud solutions is surpassing what the on-premise solutions can accomplish. However implementing these new platforms requires a plan in place for both how data will land in the cloud and how it will be consumed from the cloud. So before the code migration gets started in earnest, a Solution Architecture needs to be defined. Additionally, many of these new database solutions like Snowflake require a well-defined Access Control plan to use some of the new features for data sharing and mixed Data Lake/Data Warehousing use cases. This will also impact where integration code execution occurs after the code is converted.
#6 Not Defining the Production Promotion Process

Organizations often have managed services for maintaining their production environments. Along with this, there are often gate-keeping measures for how to promote something to production. Organizations need to dust off their requirements for production promotion so they understand what all goes into that process. For example, it could be that there is an enterprise scheduler that is responsible for executing jobs which injects code into the SQL, and thus needs to be accounted for in the end converted code. The code conversion project team needs to open a dialog with the production promotion teams to ensure the two are aware of the processes which will be eventually intersecting.
This, by the way, is part of the reason code conversions require adaptable automation tooling. There will be a surprise in every code conversion project. There's simply no way of encapsulating 20 years worth of code into an end-to-end requirements document.
#5 Injecting Too Many Enhancements During the Code Conversion Process

There is no universal consensus that says you can't capture technology advancements in the target solution during a conversion. After all, the code patterns can be defined in any way. However, don't forget that the organization will need to ultimately conduct a data test of all the converted code. Should the data not match, where is the problem? If the code is highly modified from the original code, it could inject complexity at a moment where it's least needed. If there are too many upgraded dependencies, it can inject a testing nightmare into the conversion. So non-critical enhancements are best left after the conversion project is complete. In Intricity's past experience, most performance enhancements happen natively simply through the adoption of the more capable indexing and query engine in platforms like Snowflake. If there are stored procedures or other aspects that can be optimized, we recommend conducting them after all the data testing has completed. This ensures that the milestone of a successful conversion is not in doubt, and the organization can make edits moving forward. Additionally, making edits to logic in Snowflake is far simpler with the capabilities of a Zero Copy Clone.
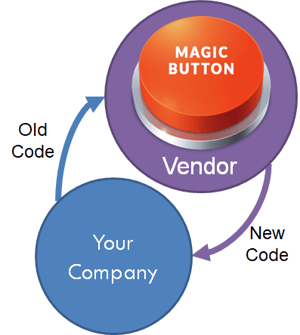
#4 Thinking of Code Conversion Tools as "Magic Buttons"
Any breathless sell of a magic button should be met with immediate skepticism. Consider that your existing code base is likely over a decade old and the skeletons ARE there. There are vendors on the market that do sell code conversion as an "over-the-wall" event.  In other words, code gets pushed over the wall to the conversion team and code gets sent back converted. The problem with this approach is that it leaves the customer to button up discrepancies. These dependencies have turned many conversions into absolute nightmares, leaving the project owners out to dry with delivery dates that are VASTLY greater than estimated.
In other words, code gets pushed over the wall to the conversion team and code gets sent back converted. The problem with this approach is that it leaves the customer to button up discrepancies. These dependencies have turned many conversions into absolute nightmares, leaving the project owners out to dry with delivery dates that are VASTLY greater than estimated.
If you can't put your hands on the conversion tool then you can't adapt the tool to patterns that aren't passing data testing or passing compile tests altogether. Avoid situations where the tool is a black box you can't put your hands on.
Rather than thinking of your conversion tool as a magic button, think of it as a cyclical adaptation solution. This cyclical process treats the code as a pattern, with base patterns in place you adapt those existing patterns to meet exactly what you want to see on the other end.
#3 Using an "Educated Guess" to Forecast the Amount of Code in the Legacy Environment
Organizations have to build their budgets for these conversions, so often there is pressure to estimate the amount of objects nested in those solutions. The issue with this pressure is that it often results in knee jerk counts of objects and flippant allocations of their complexity. What started with high-level estimates end up in RFPs to vendors as the official counts to determine scope. Once a Systems Integrator is selected and the deployment is well under way, that becomes the moment that the organization and the Systems Integrator discovers that the project has double the number of objects than what they estimated. Obviously not the moment for this to happen.
To avoid this kind of nightmare, Intricity uses BladeBridge Analyzer right out of the gate. This is a free event which allows all the code and its complexity to be tallied. Intricity has found manual estimations of jobs and complexity to be off by more than 175%.
#2 Not Defining the Testing Effort
There are 3 types of tests each with their own level of validation.
Compilation Test
The first and simplest testing method is a compilation test. This test does not require any data to deem a pass or fail. This is simply a validation whether the target technology can actually interpret the code injected. While this test is important, it doesn't really prove the conversion. For instance, you could simply add a "//" and comment out code, and this would pass a compilation test. Not exactly a code conversion.
Data Test
The second test is a data test. This is where data is actually passed through the code to determine whether the data matches the old system. 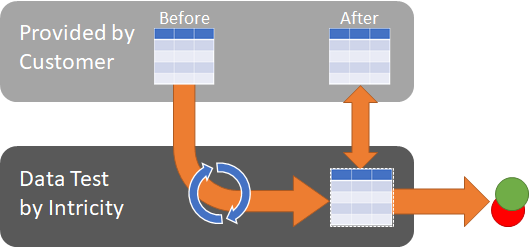
The preference is to test by subject areas. 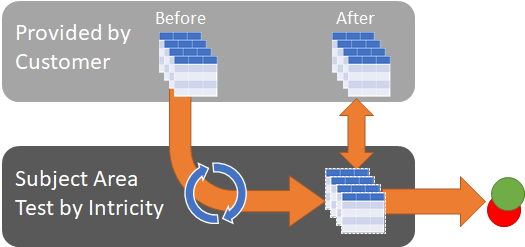
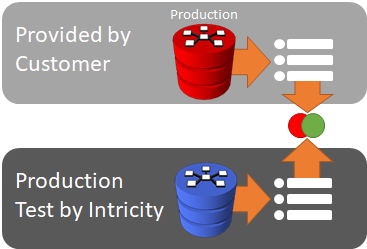
Regression Test
#1 Assuming You Can Run Your Code Conversion as an Over-the-Wall Event
This is a variation on the "Magic Button" myth. The ability to convert code is a function of automation and adaptability. If it sounds too good to be true, you REALLY should be skeptical. The cloud vendors are starting to use conversions to "buy" their clients. The problem is that the "magic conversion" claims are getting a little too fantastical with the end result being a client that is just "pregnant" enough that they can't back out of the conversion project when it's not meeting expectations. While the cloud vendor might take it on the chin, it's not without some undue shortcuts had the estimations been more in line with reality.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
