

Written by Jared Hillam

The Critical Identity
The Identity Resolution problem has been around as long as we’ve been keeping databases of records. The issue has always been: how do we identify that this record is the same as another if we do not have a “key” to match them on? Many use cases that exist are directly helped by the solution described in this white paper. We will focus on just two. Fraud prevention and the emergence of the California Consumer Privacy Act (CCPA) along with the General Data Protection Regulation (GDPR) are driving organizations to refocus on their customer identity across their various application systems. Fraud detection requires analysis on the activities being performed in real-time against a known identity. Knowing that it's the same entity making a transaction A and the exact same entity making a transaction B allows us to correlate the risk. Amongst other requirements, CCPA and GDPR require organizations to fully unsubscribe or even delete their customers' contact information across all their data systems should the request be made. If organizations only had 1 system housing customer information, this challenge wouldn’t be so sizable, but many organizations have dozens of application databases housing customer information. Multiply that by how many requests are regularly made to unsubscribe/delete records, and the impact quickly becomes a burdensome manual expense. This expense surfaced the need to automate the resolution of customer identity in an efficient and scalable way.
Snowflake
Snowflake provides a data platform which can handle large quantities of data, while maintaining a very agile compute footprint. Additionally, Snowflake has the unique ability to clone iterations of data without duplicating the data footprint. This makes it the perfect solution for dealing with iterative machine learning data sets.
Intricity Identity Resolution Engine
Intricity leverages Snowflake to deploy the data sets generated by its Identity Resolution solution. This solution is a guided machine learning engine which users can interact with to validate examples of matching identities which can include fields such as:
- First/Last Name
- Phone Numbers
- Email Addresses
- Physical Addresses
- Geo Location (lat/long)
- Loyalty Card Numbers
- Credit Card Numbers (hashed/salted)
- Other Identifiable Information
The ML engine iterates with your data SMEs to generate a model of your customer identities. After training, this model can then be unleashed to automatically generate clusters of pattern matched customer identities across all the sources of data fed into it.
Data Onboarding
The architecture of the Identity Resolution starts with onboarding all the data from the various sources into a Data Lake. Preceding the Data Lake is a Landing Zone which shields the Data Lake from the chaos of onboarding live streams of data. The triggering and loading of data happen live from the Landing Zone to the Data Lake via Snowflake Streams and Tasks.
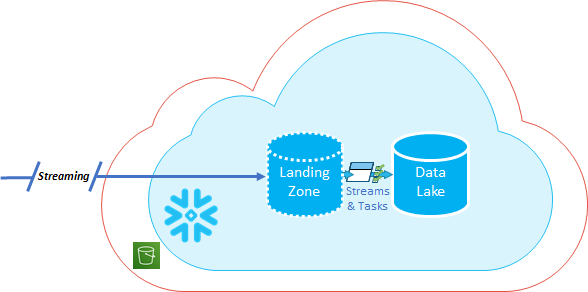
Landing Zone
The Landing Zone is a place intended for automated processes and not for human hands. This enables the Data Lake to represent pristine source sets which the various downstream systems (Data Warehouses, Data Science, Operational Reporting) can leverage.
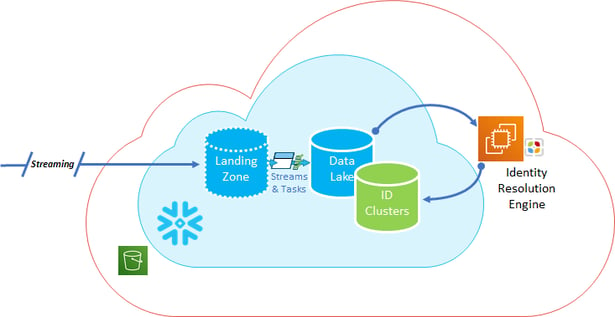
Data lake
In the Data Lake, we define how sensitive data appears to the user community, whether it's providing tokens, a range of values, or presenting no data at all based on user roles. By defining this in the Data Lake, we can build a consistent foundation for data security for all the downstream use cases. To enable the Data Science community in the Data Lake, we define cross-references which the Data Science community can leverage in their day-to-day analytics. Additionally, Intricity designs specialized security access points which shield the Data Science teams from production processes, while allowing all the capacity to experiment on the entire data set production it leverages. These are locations Intricity calls “Data Islands” and this capability is something Snowflake uniquely allows us to deliver through Zero Copy Cloning. The Data Lake acts as the foundation for our ID Clusters generated by the ML Engine.
Training the ML Model
Intricity’s Identity Resolution adds another data set to the Data Lake which contains the Identified Clusters from the trained Machine Learning. These identified clusters represent the consolidated clusters of customer records that the engine has grouped together. Once the training interaction with the SMEs is completed the full historical record set is run against the Identity Resolution engine. This will produce an auditable cluster of matching IDs that the organization can fully audit and use for querying.
Identity Matches
When the Identity Resolution Engine acquires a match, it will add a unique identifier to the record which it clusters. Additionally, it will add a confidence score next to each record in that cluster.
Duplicate Records
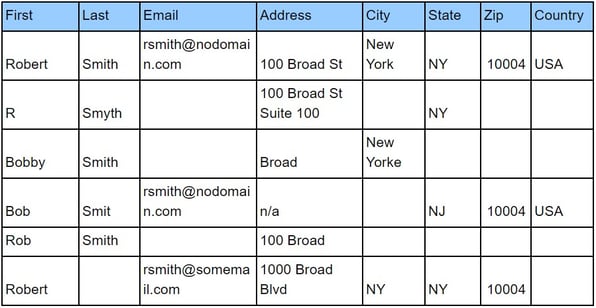
Cluster ID and Confidence Scores Columns Added
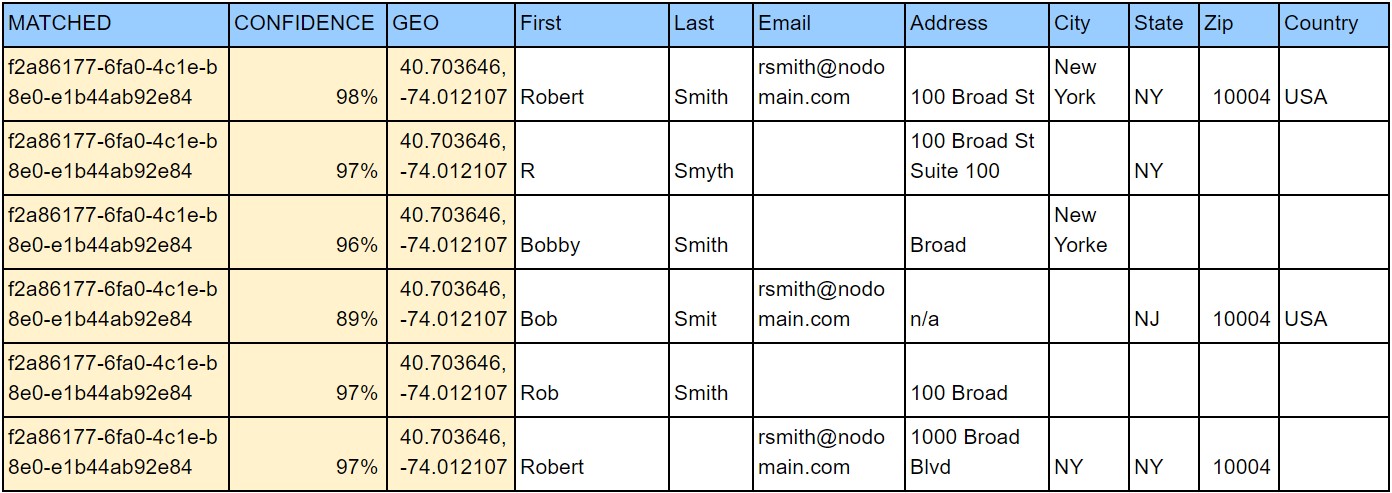
These Cluster ID tables live in the Snowflake Data Lake and can be leveraged for a variety of processes and downstream solutions.
Making it Live
To hook this up to the existing Unsubscribe request systems in the organization, Intricity has enabled an AWS API Gateway which can communicate securely to a Snowflake Queuing Database, which will generate active matches and log those matches along with any exceptions during the unsubscribe attempt.
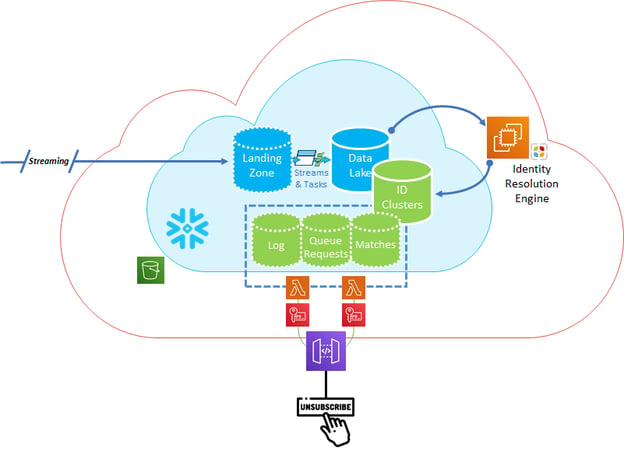
This solution not only ensures that the Unsubscribe is logged, but also identifies the unsubscribe against all the varied identities that match the Unsubscribe request. Additionally, the solution leverages Snowflake’s powerful compute, storage, and metadata pointer architecture which allows the ID Clusters to be easily accessible to the Data Lake, and all the downstream consumers.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
