

Written by Jared Hillam

We all remember the story of Goldilocks and the 3 Bears. Through the process of elimination Goldilocks eventually finds an option that is “just right.” When it comes to Enterprise Software, companies have to go through the same bad experiences, but they often don’t find an option that is “just right.” Unfortunately for most organizations, it's too difficult (and too expensive) to fully go through this process of elimination. Not that organizations don't try, there are demos, POCs, RFPs, and pilot programs. However, none of these attempts allow companies to see the end result over an extended period of time. So especially in the analytics space, we end up finding that the sexiest and most interactive user interface wins the prize, only to find out later that there are major technical holes which keep it from being adopted company wide or for big datasets.
For Intricity (the consulting company I work for) we get to experience the full Goldilocks process of elimination by being introduced to new organizations on a consistent basis. This opportunity provides us a unique view into the shortcomings of certain approaches for turning data into information. In this white paper, we’ll share a couple things Goldilocks would have noticed about the Enterprise Analytics solutions that are “Too Hot”, “Too Cold” and “Just Right.” Let's go with the assumption that our goal is to support the broadest possible audience in an organization.
Querying Data
Too Cold- Raw SQL
 About 14 years ago I worked for a software company that sought out to fix a common problem found in Operational Reporting. We developed a product that allowed you to open 1000s of operational reports and edit all of them at once. Why was this even necessary? Well, operational reports allow you to nest the data gathering logic as part of each report template or file. So in other words the logic is part of each individual report. Eventually, organizations would find themselves with literally 1000s reports, each with their own nested logic. The drawbacks of having logic spread out like this became pretty obvious. Often the organizations would have to change certain calculations which were part of the file. This meant that 100s if not 1000s of reports had to be manually opened... edited... saved... and republished in order to account for the changes.
About 14 years ago I worked for a software company that sought out to fix a common problem found in Operational Reporting. We developed a product that allowed you to open 1000s of operational reports and edit all of them at once. Why was this even necessary? Well, operational reports allow you to nest the data gathering logic as part of each report template or file. So in other words the logic is part of each individual report. Eventually, organizations would find themselves with literally 1000s reports, each with their own nested logic. The drawbacks of having logic spread out like this became pretty obvious. Often the organizations would have to change certain calculations which were part of the file. This meant that 100s if not 1000s of reports had to be manually opened... edited... saved... and republished in order to account for the changes.
So the lesson learned is, don’t tie the visualization and the query at the hip. If they are tightly coupled up then you won’t be able to keep your data visualizations up 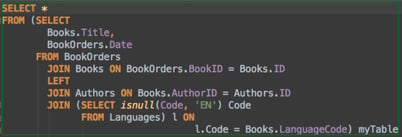 to date with your changing business. Believe it or not, this lesson is now having to be relearned as new BI vendors are emerging that have sexy visualizations but each visualization has its own SQL query…
to date with your changing business. Believe it or not, this lesson is now having to be relearned as new BI vendors are emerging that have sexy visualizations but each visualization has its own SQL query…
Too Hot- In Memory Analytics
Analytics solutions that leverage in-memory data sets often suck all the data into the Analytics Suite so that it's “ready to eat”. Imagine having your entire analytics experience, including its navigation, all prepared ahead of time and sitting in memory for you to use. Many vendors take that approach. However, that approach was actually born out of necessity well over a decade ago. Just think, a server from 10 years ago would be blown away by your average laptop’s processing power today. So relational databases at the time simply couldn’t deal with the onslaught of queries requesting millions/billions of rows of data. To deal with this, analytics vendors designed their solutions to draw all the data into memory, providing a smooth user experience. But this in-memory approach also means that every possible drill through has to be pre-processed which leads to a large number of wasted calculations because no one will drill into every possible scenario.
 However, this pre-calculation certainly does solve the decentralization of logic problem, and it sure beats having SQL queries floating around in the ether. The problem however is that BI pre-calculation takes the centralization solution too far. Rather than just centralizing SQL logic, it commits all the data to a final analysis state. Like getting legos for Christmas but finding they are superglued into components rather than individual bricks.
However, this pre-calculation certainly does solve the decentralization of logic problem, and it sure beats having SQL queries floating around in the ether. The problem however is that BI pre-calculation takes the centralization solution too far. Rather than just centralizing SQL logic, it commits all the data to a final analysis state. Like getting legos for Christmas but finding they are superglued into components rather than individual bricks.
Another huge downside of pre-calculation is the necessity to move the data into the vendors solution. One of the central tenants of big data strategies is to leave the data where it lives. Wherever possible take the query to the data and not the data to the query. You don’t want to be stuck extracting mass quantities of data into a proprietary layer.
Where In-Memory Makes Sense
Where in memory analytics DOES work is the R&D/Data Science function. The in memory nature of these solutions enables a high level of individual discovery. This is where using a Data Lake of raw data also makes some sense.  If I’m trying to make a discovery in my data, then structure can at times get in the way. For example, I may want to add some weather data to my analysis to see if there are correlations. The Data Lake makes that all possible because it’s designed to be a landing bed for raw data.
If I’m trying to make a discovery in my data, then structure can at times get in the way. For example, I may want to add some weather data to my analysis to see if there are correlations. The Data Lake makes that all possible because it’s designed to be a landing bed for raw data.
The trap that organizations fall into is in applying the allure of in memory analytics tools to mass information distribution. The genesis of these tools was designed for discovery and not dissemination, so when they get rolled out for such they often fall flat on their face.
Just Right- A Metadata Layer with a Data Warehouse
Before I get into this, let me share a good comparison that will set the stage for my later points:
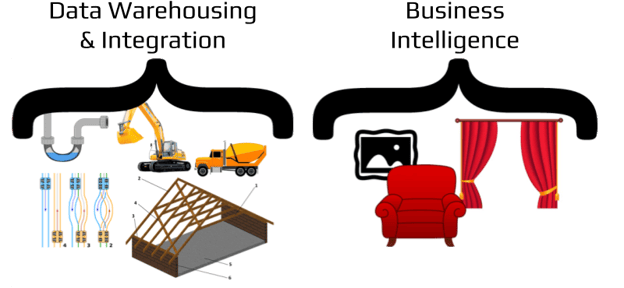
A picture is worth a 1000 words… So the guts of the home, its foundation, electrical, plumbing, framing, roofing etc are like data warehousing and integration. The decor on the other hand represents Business Intelligence. I’m not minimizing the role of Business Intelligence. Quite the opposite, think about what you see when you enter a house… you see the decor. People judge a home based on that, just like they judge your data based on your BI. But does the decor matter if you have bad plumbing or the foundation of the house is collapsing? Additionally, how often do you change the decor? I would guess that most homes have their decorations change every few years. The same could be said for Business Intelligence tools. There is always going to be a shiny new tool to get your hands on. BUT you don’t throw away the whole house so you can put up new decorations!
The problem that most companies have is that they purchased the decor (BI Tools), but they don’t have a house (data management foundation) to put it in! So rather than building the house they try to make the decor the house. Or in other words they try and stuff as much integration and conformity logic into their new BI tool, only to find out that they’ve locked that logic into a proprietary vendor, never to see it used elsewhere. So the day a new visualization method comes out which isn’t part of your existing BI stack, you’re stuck.
Scalability? It’s ALL about conforming data
Over the last 4 years we’ve heard endless droning about how important Data Lakes are. But the Data Lake only solves the locality problem. Meaning it keeps me from having to individually connect to all the disparate databases. It does this by loading all their data into a single data store (Data Lake). Big whoop… What good is having a bunch of data in one place to business users if it doesn’t conform? While that may be good enough for Data Scientists, there’s an entire population of business users that are left starving for information, because they’re navigating a sea of raw data which is locked in a tangled web of logic required to make it meaningful. I’m being harsh on the Data Lake because far too much emphasis has been placed on it at the cost of many failed corporate projects. The Data Lake does play an important role as being a place data can be centralized and experimented with, but it’s not where business users should be left to their own devices. So the Data Lake is only a preamble to the hard work of building the Data Warehouse.
A disciplined Data Warehouse deployment delivers conformed data that can be shared across process owners, management, and down the line. This is because the hard work of untangling that web of complexity gets heat, light, and focus in an effort to automate its conformity. What secures that investment is the fact that the Data Warehouse is a database, queryable by ANY analytics tool. This is partially why there is no need to pre-calculate data (too hot example) if you have a data warehouse. However, the existence of the data warehouse doesn’t eliminate the need to control your BI content like our “too cold” example.
The Metadata Layer

So how do we centralized without pre-calculating our results? The answer is a BI Metadata Layer. This is a layer which exposes data objects to users without storing the data behind those objects physically. When the user clicks on a data object it produces the SQL necessary to retrieve the data which that object represents. The BI Metadata layer can be used to combine and rename data objects so they use the terminology the business understands like Date, Customer, Address etc.  Used in conjunction with the Data Warehouse the users are delivered atomic and flexible data components which can be shared across the organization... like Legos. The vendors that truly embrace this methodology leave the heavy lifting to the non-proprietary data warehouse, and avoid pre-calculating their results.
Used in conjunction with the Data Warehouse the users are delivered atomic and flexible data components which can be shared across the organization... like Legos. The vendors that truly embrace this methodology leave the heavy lifting to the non-proprietary data warehouse, and avoid pre-calculating their results.
This also enables individuals within an organization with a tremendous amount of latitude to query their own results. So even for people needing to do research, the metadata layer can facilitate that function without resorting to the deployment of an in memory solution.
This combined methodology is “just right.”
The Cloud
Too Cold- Born On Premise
The business intelligence industry has been around for over 20 years, so obviously there are a lot of behind-the-firewall options out there. But transitioning to become a cloud company is not just a slight change. Things get messy really fast in that sort of transition.  Transitioning software companies have to deal with a new compensation model for their sales reps, a split R&D budget, a split support team, a split solution architecture, and a whole new foundation for funding the operation.
Transitioning software companies have to deal with a new compensation model for their sales reps, a split R&D budget, a split support team, a split solution architecture, and a whole new foundation for funding the operation.
The question is, do you want to marry yourself to a vendor that is going through something like that? The vendor is having to do more with less, and very very few make it through the process. There's a really good book about this process called The Innovator's Dilemma, by Clayton Christensen.
Beyond the obvious business challenges, there's also some serious architectural challenges to deal with. Usually vendors that make this transition take their existing methodology and adapt it to a cloud architecture. The problem is, since they don't start from a clean slate they usually miss the innovations the cloud brings to the picture. The reason why is fairly obvious, they have to be able to provide a migration path for existing on-premise customers to ultimately land in the cloud. So they can't just adopt the advantages the cloud brings because they need to stay compatible with their legacy solutions.
Legacy of Proximity
 Legacy business intelligence vendors always had the luxury of being in close proximity to the data. However a move to the cloud requires a solution to respect a much lighter query footprint. Because it makes no sense to be moving mass quantities of data over the wire. But this is how many BI Solutions have been fundamentally designed, particularly the in-memory solutions.
Legacy business intelligence vendors always had the luxury of being in close proximity to the data. However a move to the cloud requires a solution to respect a much lighter query footprint. Because it makes no sense to be moving mass quantities of data over the wire. But this is how many BI Solutions have been fundamentally designed, particularly the in-memory solutions.
So, as you can see, I'm naturally skeptical of legacy BI vendors that tack the word “cloud” after their logo, and you should be as well.
Too Hot- Born for a cloud

There have always been a lot of vendors in the business intelligence space. But these days, it's especially the case. Established cloud vendors seem to be releasing BI platforms as a side hobby. This makes sense as SaaS application vendors can indeed deploy their BI platforms in close proximity to your SaaS application data. The problem however is that BI is ideally agnostic to data sources.
Ten years ago, BusinessObjects was an independent BI platform which was considered the Switzerland of BI tools. Then SAP acquired them. As much as BusinessObjects emphatically insisted that they remained an unbiased BI platform, the windfall of R&D to support SAP clients didn’t go unnoticed. Today, BusinessObjects is squarely an SAP tool… They aren’t even invited to the party if SAP applications aren’t involved. The same is true for Oracle OBIEE, their name doesn’t come up unless the customer has a significant Oracle Applications footprint.
When you deploy the process of turning data into information, you don’t want to rely on any one application stack. In fact you want to do the complete opposite, your applications should be replaceable as commercial off the shelf deployments. You should be able to replace your applications without turning the lights off to your data-to-information process. Vendors that package BI as a side dish to a larger SaaS application should be looked at with the same skepticism as BusinessObjects and OBIEE. If your organization has boundaries that surpass a single SaaS application, then I would recommend using a neutral and agnostic cloud BI platform. That would represent… pretty much everybody.
Just Right- Born in the cloud
A true “born in the cloud” business intelligence vendor must solve the problem of issuing queries to a database that might not be in the adjacent server rack. To solve this challenge they need a methodology that maintains analytical flexibility without requiring all the data to be uploaded for pre-processing. Additionally, the query should only contain what the user requested and nothing more. Again, we land squarely on the BI metadata layer as the most ideal way of balancing the control of content with the light touch data footprint required for the cloud. When these requirements are met, the data transfer is actually very lean. But this all means that a cloud BI solution needs one very critical component, a highly performant data source.
So once again, a well modeled Data Warehouse provides an ideal source for a metadata layer to access data from. The data model in a Data Warehouse doesn’t just make the SQL queries pithy, but it provides highly responsive results when queried. This responsiveness is particularly true for cloud based Data Warehousing solutions which separate compute and storage as well as automate query optimization.
Tried and True
The architecture that I've mentioned in this white paper is not something that I recently invented. These are methodologies that have been created as a result of extensive trial and error by hundreds of companies. Ironically, this proven method is new to most people that have been struggling at cutting edge startups to figure out how to set up their data-to-information processes.  It turns out that the Big Data hype from 5 years ago derailed the awareness of really solid best practices in data management. For those that come from the data management space, the trough of disillusionment couldn’t come soon enough. They could smell the snake oil from miles away. Within the last 2 years, the market has seen the light, and has adopted what is good about Big Data architectures and stopped selling it as an end all solution. Combining the strength of cloud with a data lake, data warehouse, BI metadata layer, and a rich and open BI visualization layer has proven itself as “just right.”
It turns out that the Big Data hype from 5 years ago derailed the awareness of really solid best practices in data management. For those that come from the data management space, the trough of disillusionment couldn’t come soon enough. They could smell the snake oil from miles away. Within the last 2 years, the market has seen the light, and has adopted what is good about Big Data architectures and stopped selling it as an end all solution. Combining the strength of cloud with a data lake, data warehouse, BI metadata layer, and a rich and open BI visualization layer has proven itself as “just right.”
While the architecture is tried and true, the cloud technologies to enable it have never been better. I recommend you reach out to Intricity to talk with a specialist, we can help you develop a reference architecture to take you into a best of breed data-to-information solution.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
