

Written by Jared Hillam
The 10 Year Problem

10 years seems like an eternity ago when it comes to data management technology. 10 years ago (2009) Hadoop hadn’t even really gone mainstream yet, and AWS S3 had only been around for 3 years.
Just for a moment, imagine that you have to maintain a data integration environment for over 10 years. How would you deal with the changing landscape of data? How would you deal with the whims of tooling that both business and technical stakeholders try to deploy? Maintaining a data integration landscape for 10 days is enough, let alone 10 years.
One of the biggest problems in maintaining a data integration environment is the maintenance of logic. Having logic scattered across an enterprise about “how data integrates” is a major barrier to successfully maintaining a data integration landscape. At some point the code becomes too complex and the users become too unaware of what is there, so eventually a new integration project spins up. This happens despite the code being presented in a nice “Visio like” interface as is produced in many ETL tools. One of the contributors of this disbursement of logic is developer nuance. Each developer has their own way of coding certain ETL or SQL tasks. This nuance makes it hard to manage a large data integration landscape with confidence. Some ETL tools provide mappings as reusable parts, but it's incumbent on the developers to use those mappings.
Patterns
Most every action in data warehousing and data integration development follows distinct patterns and best practices. The best ETL developers follow these patterns like gospel because it ensures their code is highly predictable. So if they need to go back and audit something, the task is made easier. If you only have 1 ETL coder over the lifetime of your data integration landscape, perhaps this could be the answer to the “10 year problem”, but that’s nearly impossible. Good ETL Architects will typically leave a Program Charter which spells out all the development patterns and naming conventions in the hopes that other ETL developers will follow suit. Again… in theory wonderful, but in reality, nearly impossible...

A data integration project, typically sees MANY helping hands over its lifetime (and unfortunately, many not so helping hands). Establishing these patterns is usually only possible through the use of a code generation engine. With such tools, the development code is auto generated after the data analyst configures what output they are seeking, so things such as setting up aggregations, joins, filters, splits, etc., are all pre-configured. All the organization needs to do is specify the desired data integration action in a much simpler analyst interface.
The use of pattern based code generation has some obvious time to market benefits as well. Rather than manually setting up mappings within an ETL tool, or developing transformation SQL statements, this code is automatically generated.
Avoiding Lock
Going back to our goal of maintaining a 10 year integration environment, one thing that we must deal with is vendor lock. Over a span of 10 years it is easy to get locked into a piece of technology that you can’t budge away from. What this means is that you want to keep your run-time environment as free as possible from niche, fly-by-night vendors. Any solution that is in the critical path of the data-to-information process needs to be stable over the long run.
Not all code generation tools meet this criteria. Many purposefully embed themselves into a runtime environment to ensure they are deeply rooted into a predictable revenue stream. This is not something that is sustainable for large enterprises that are seeking massive scale and cost performance. So a key component to code generators is the ability to generate code for other runtime environments. Additionally, the outputting code needs to run independently of the code generator. So if the code generator were no longer used and ultimately turned off, the existing code that was generated would run with no strings attached. That is a tall order, and requires the support of many runtime environments as there are many ETL and SQL tools on the market. So how do independent code generators deal with this problem?
Inheritance
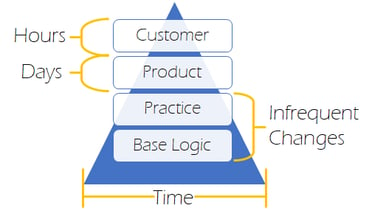
Independent code generators use inherited configuration layers which break apart the various levels of customization from customer to customer. Let’s take a join statement for example. The base logic for how to do a Join is going to be fundamental to roughly any database type. The practice logic for how a Join engages with other mapping objects, and its naming conventions are stored in an agnostic configuration. The product logic which is specific to certain syntaxes and nuances related to a certain database or ETL tool is what enables the code to be natively generated for your chosen platform. Then last but not least, is the customer logic that is specific to the customer’s use case. This is the content generated by the data analyst, which includes customer functions, and other things that you would commonly find in a source to target mapping document.
This inherited logic provides loose coupling of the fundamentals and practices from the product and customer nuances. Often when code generators need to create a new target code platform, (say PySpark for example) the on-boarding of that new target is measured in days and weeks rather than months. This is because the base and practice logic are already established so the focus is simply on mapping the code objects against the existing agnostic metadata.
Being able to access these configuration layers is an important nuance which separates code generation engines. Some keep those configuration details hidden as proprietary. Others provide full access to such logic so development and coding patterns can be fundamentally shifted over time. This doesn’t often occur, but remember we have to be able to solve the “10 year problem”
Rising Out of Obscurity
When you cut down all the requirements for such a tool, you quickly realize why these tools are so “invisible." They scarcely take the limelight because they don’t live in the runtime environment. Their role is geeky enough that few have actually put their hands on one. However, those that have gotten their hands on solid code generation for data projects will never go back. The speed of deployment and consistency of code completely change the cost and complexity of data integration endeavors.
10 Year Integration Environment
Recently I visited a large Financial Services firm in New York City. They showed me a very robust Data Warehouse which they’ve been using for over 10 years. The typical grievances of “the old warehouse” were simply non-existent. They had successfully kept their architecture up to date, migrating their code from platform to platform as the winds of change came through. The code was the asset, not the tooling around the code, which is the way it should be. The consistency of the code made it auditable, and the code generator made the code transferable. They had automated documentation and lineage. Perhaps more importantly, the code was theirs. I’m convinced this is the solution around “the 10 year problem."

Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
