

Written by Jared Hillam

Snowflake has changed the data consumption market. Tasks that used to take weeks & months of tedious effort are no longer required. If you're not familiar with Snowflake, our ‘What is Snowflake’ whitepaper should give you a solid introduction. While Snowflake is amazing, there are definitely mistakes that organizations and consultancies can and do make in deploying it. With Intricity entering its 6th year of consulting on the Snowflake platform, "we've seen everything" is not an exaggeration. However, after 6 years Intricity also generated a lot of quick solutions around some of the “easy to address” mistakes. So the forthcoming mistakes are skewed to the bigger bungles, but maybe not the most common.
#1 Configuring Access Controls Tactically
Snowflake is VERY secure. In fact, turning encryption off isn’t even optional. When it comes to external parties trying to breach its security, Snowflake is a formidable foe. However, dealing with internal designations of “who gets to see what data” is an entirely different realm of security and a place where many organizations have made some big mistakes.
One of the most common answers to the question, “why does Snowflake do it that way” is... micro-partitions. The magic of being able to have all this computational flexibility, parallel speed, instant cloning, and time-traveling, comes with a few linchpins. This can be manageable but organizations must take these linchpins seriously.
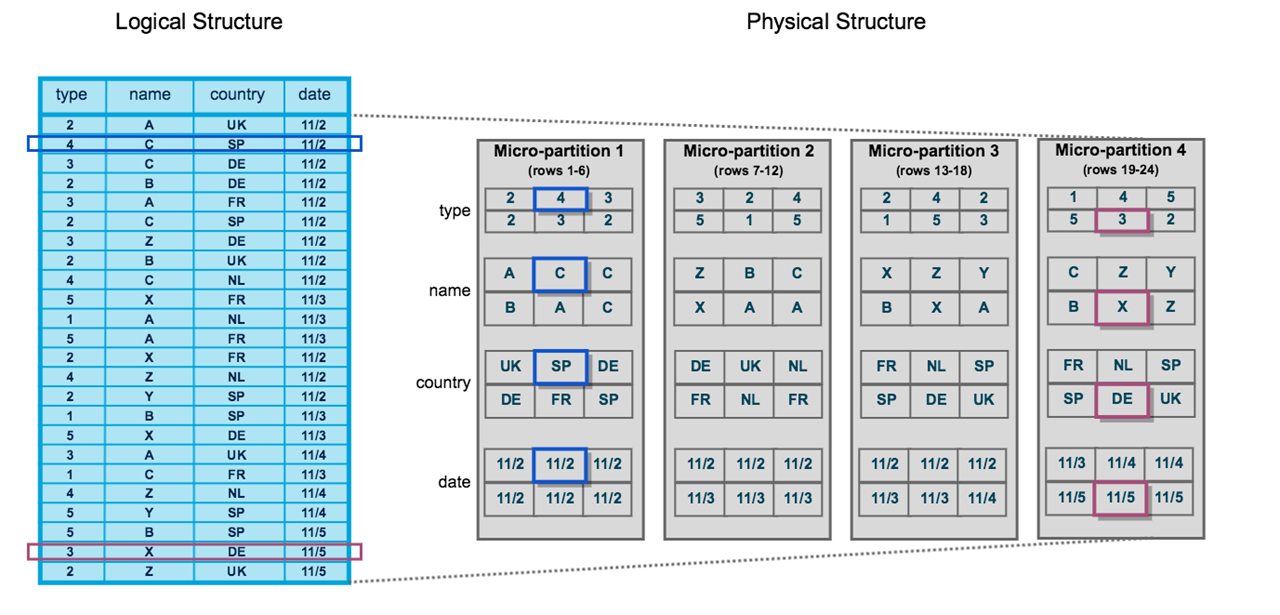
The first thing to understand about Snowflake’s access control is that the structure is inverted to what most people expect it to be. In other words, instead of having a parent-to-child inheritance, where children objects inherit from their parent object, 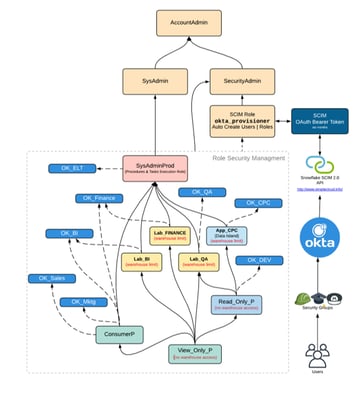 you have an inheritance-up model where the parent inherits what the child object can do. This confuses administrators that have a preconceived assumption that rights are combined based on what roles the user is assigned. Snowflake doesn’t do this at all by default. Users that are assigned to roles don’t inherit all the rights of the combined roles they participate in. In other words, you can only use one role at a time. This becomes complex to define if you want to create a role that provides a specific slice of data access. Flippant deployments here can lead to some of the most egregious issues to untangle. Here are just a few:
you have an inheritance-up model where the parent inherits what the child object can do. This confuses administrators that have a preconceived assumption that rights are combined based on what roles the user is assigned. Snowflake doesn’t do this at all by default. Users that are assigned to roles don’t inherit all the rights of the combined roles they participate in. In other words, you can only use one role at a time. This becomes complex to define if you want to create a role that provides a specific slice of data access. Flippant deployments here can lead to some of the most egregious issues to untangle. Here are just a few:
Role Sprawl
When proper access control management isn’t understood we see “Role Sprawl.” This is where administrators end up creating an independent role for every use case multiplied by every Tom, Dick, and Harry. This is usually done as a bandaid because users couldn’t see certain content, and administrators couldn’t successfully grant access (which we’ll discuss below). So a new role gets spun up for that specific need. The natural outcome is a totally unmanageable set of roles that have no centralized governance whatsoever.
The other reason we see Role Sprawl is because administrators end up with so many roles that they don’t even know what the existing ones do. Meanwhile, they’re unwilling to delete them because they fear the prospect of breaking the inheritance of other objects. This is a compounding problem as more roles get created.
Chasing Grants or Stacking Roles
The alternative to a new role is the practice of “chasing grants” which assign or revoke privileges to Snowflake objects (like tables, views, schemas, roles, and warehouses) to a specific role until everybody is nearly a system administrator or unable to access anything at all. The issue here is usually a result of administrators not being cognizant of the bottom-up inheritance. On top of that, the administrators don’t document the new grants they make. However, Snowflake’s inheritance can muddy the water because administrators can’t tell from the UI how an object is inheriting grants from other roles. So administrators can often have difficulty not just with grants but also revokes. This can become a tangled web depending on how far an organization has gone down this rabbit hole. Drastic mistakes can occur here, with administrators pulling out the sledgehammer instead of the scalpel, and granting/revoking access across all the roles in the deployment. This only further tangles the rat's nest.
System Administrator for All
Another common practice is where organizations give up on setting access controls altogether by granting everybody as a System Administrator, essentially allowing every user to see everything. This is fine for a tiny startup, but it wouldn’t pass the most basic CISO test in larger organizations.
#2 Throwing Credits at the Problem
 Snowflake’s amazing abilities to scale compute can really get an organization through some challenging binds. Queries that were simply impossible to run in past platforms are now possible to execute. However, this also means that organizations must pay for the compute related to such queries. Big compute allocations should be the exception and not the everyday rule, otherwise, customers will incur steep recurring costs. The remedy is to invest in solid engineering. Clients are amazed at how much impact this kind of engineering can have.
Snowflake’s amazing abilities to scale compute can really get an organization through some challenging binds. Queries that were simply impossible to run in past platforms are now possible to execute. However, this also means that organizations must pay for the compute related to such queries. Big compute allocations should be the exception and not the everyday rule, otherwise, customers will incur steep recurring costs. The remedy is to invest in solid engineering. Clients are amazed at how much impact this kind of engineering can have.
Without proper engineering in place, clients seemed puzzled why their costs are not in line. There are, however, a few engineering mistakes that end up having an outsized impact:
Massive Inefficient Tables
Snowflake can handle large tables with the best of databases. However, a really large table can also create unnecessary compute overhead. Here are a few ways that tables can get mismanaged.
Ignoring Sort Orders During Loads
Snowflake stores the micro-partitions in the order the data loaded. So if an organization just loads data without any sorting, it will push Snowflake to process more than it should. For example, a common selection criterion is a Date field. If your data consumption is based on heavily leveraging the date field then the correct practice is to load the data with the transaction dates pre-sorted.
When the data isn’t sorted (during the load) by common selection criteria, then Snowflake will use more compute power to execute the query. This is due to the way a columnar/micro-partition engine processes queries, as it leverages a min/max range to speed up the process of identifying micro-partitions to interrogate. If the dates are sporadically loaded into micro-partitions, it will force Snowflake to open many micro-partitions to find the data in order to query it. This issue really is only applicable to large tables, but can be a problem if a large table is joining to other tables.
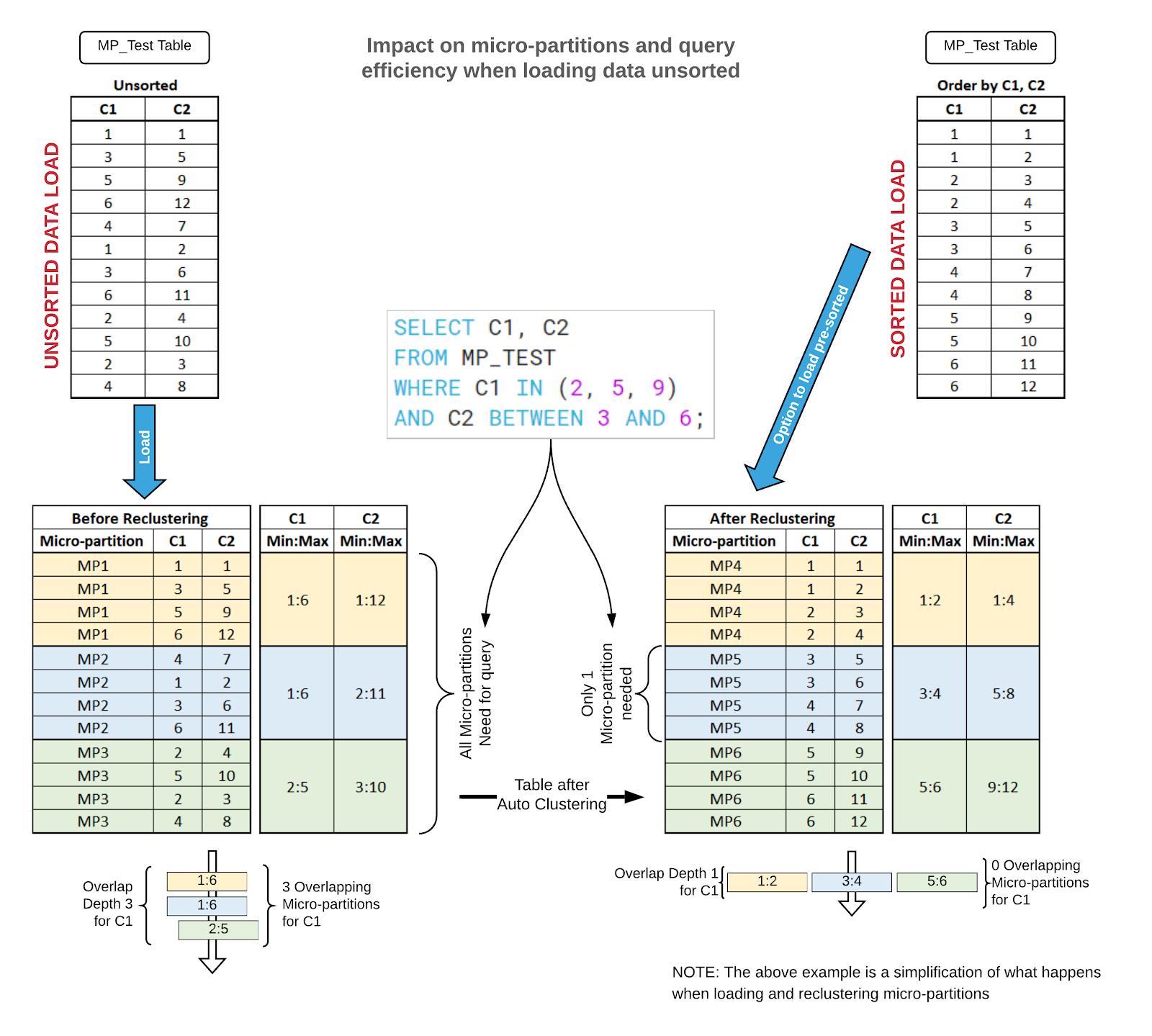
Snowflake has the ability to fix this issue even after the data has been loaded by using Auto-Clustering. This feature is great, but again it requires more compute spending to continually restructure the data for greater efficiency. Auto-Clustering is not to be confused with Indexing. Auto-Clustering is literally a physical reshuffling of micro-partitions and their contents to better align with data usage.
Ignoring Blind Updates
A blind update is an update to a record in a table that actually has not been changed. How is this even possible? Data loading uses blind updates simply because it’s the path of least resistance to capturing everything, but in reality, the data itself is not actually different. This very common practice is something that works well with traditional databases because an update won’t create a duplicate.
Unlike traditional databases, Snowflake’s data store is an immutable and absolute store, meaning an update doesn’t behave like the old pre-allocated record storage. Rather, Snowflake writes a new record set in a new micro-partition and re-routes the pointers to the new micro-partitions which is how it synthesizes the update. However, if the update has no changes in the records, this can create a HUGE fragmentation of the table storage with useless updates. This is particularly true with clients that have very noisy source application logs. In one such audit, Intricity discovered that the updates were creating more data than the entire existing data footprint multiple times per day.
The real cost to this problem comes from the fragmentation of the data in the table. This wouldn’t be the case if the entire record was in a single micro-partition. However, real-world records span multiple micro-partitions. As records gain these updates they begin to fragment between micro-partitions and the table. In one such case, Intricity was able to count that the query was spanning 200,000 layers to read the data. With proper engineering, the queries spanned 3 layers.
Another solution to this is to leave Auto-Clustering turned on. However, this requires clients to pay to store the unnecessary updates, process the unnecessary updates, compute to run Auto-Clustering, storage to run Auto-Clustering, and reallocation of storage. So while having Auto-Clustering provides an easy way to deal with these issues, it comes at a cost, which could be avoided with some understanding and engineering.
One Warehouse to Rule Them All
 A warehouse in Snowflake is basically a compute allocation scaling policy. Snowflake customers can have as many of these allocation scaling policies as they want. However, often the name “warehouse” gets users confused thinking the old descriptions of the word apply. Thus they’re nervous about creating, copying, or editing “warehouses,” and with no strategically defined warehouses configured, users often share an existing warehouse. What this often results in is users sharing compute allocations that are too overpowered for their queries. Additionally, Snowflake administrators end up seeing a warehouse that never turns off (because everybody is using that same allocated compute) thus the billing meter adds up.
A warehouse in Snowflake is basically a compute allocation scaling policy. Snowflake customers can have as many of these allocation scaling policies as they want. However, often the name “warehouse” gets users confused thinking the old descriptions of the word apply. Thus they’re nervous about creating, copying, or editing “warehouses,” and with no strategically defined warehouses configured, users often share an existing warehouse. What this often results in is users sharing compute allocations that are too overpowered for their queries. Additionally, Snowflake administrators end up seeing a warehouse that never turns off (because everybody is using that same allocated compute) thus the billing meter adds up.
This cost really kicks into high gear when a user has a very large compute task, and he/she edits the shared warehouse to match the burden, then leaves it configured that way. Subsequent users then execute their simple queries using an overpowered shared warehouse. Often organizations with a “set it and forget it” attitude discover they are paying a lot more than they expected in compute costs. On the other side of the spectrum, it’s possible to have users sharing a warehouse that is too small, and not configured for the volume.
#3 Haphazard Objects
One advantage of Snowflake is that everything is in one place. This is a welcome reprieve from other cloud technology stacks with an alphabet soup of utilities. However, with great power comes great responsibility. Data management teams need to be cautious about naming conventions, and governance. Otherwise, they will discover they have an endless sea of orphaned objects. Here are some of the more egregious challenges:
 All Objects in One Spot
All Objects in One Spot
Just as it’s possible to dump all your computer files into a single file folder, the same is possible in Snowflake. In Snowflake, an organization could dump all their objects into a single schema in one database. The downsides are exactly the same as putting everything into a single computer folder. Not only are the objects more difficult to navigate, but it makes security far more complicated to deploy. The same is true for Dev, QA, and Prod environments. Having separation here keeps big unintentional mistakes from happening to the Production Environment or important projects the teams are working on.
Way too many Spots for Objects
To piggyback on our file folder examples, too many file directories can make it difficult to navigate. The same is true in Snowflake. Too many databases and schemas can make it difficult to manage objects and secure them.
Object Sprawl
In past databases, there was always a concern about storage and compute resources. So creating objects like backups, snapshots, copies, or even adding new servers were incredibly expensive and difficult to do. This simply isn’t the case in Snowflake.

Snowflake customers no longer have arguments about infrastructure. However, this newfound freedom can be abused by creating endless objects with no regard for governance, cleanup, or ownership. As you would expect, organizations fear deleting objects because they do not know where it is being used. This is where foundational access control and governance via naming conventions becomes critical.
Here are a few common examples where Objects Sprawl can go sideways:
Warehouses
Earlier it was pointed out that sharing a warehouse could lead to costly compute overallocation. However, the inverse can also occur, where an organization has too many warehouses often not assigned to roles. In these cases, the users are exposed to a massive list of scaling policies and they don’t know which to choose. This leads to over and under allocation of compute. Having 50 warehouses appear for users to pick from doesn’t ensure proper compute usage.
Clones
One of the amazing features in Snowflake is the ability to generate a clone and not actually duplicate the data. The only thing duplicated is the set of metadata connectors to the immutable storage layer. However, because this is easy to do, organizations can overdo it and make end users confused. This is especially true when there is no naming convention in place to organize the object clones. This can result in data objects getting created which are orphaned over time.
A clone has no cost for storage… until it does. At the inception of the clone, the clone has 100% of its pointers connected to the originating object. Any deviation from that point forward will create a new micro-partition for the originating source or the clone. Also, any deleted objects from the originating source will not delete the pointers because the orphaned clone still has them active. Thus over time the storage footprint progressively grows unnecessarily.
Confusing Front End-Users with Back-End Objects
As was mentioned earlier, Snowflake is one big happy place. So when naming conventions for the database schemas and objects are inconsistent and difficult to interpret it can become very confusing for end-users. This is particularly true when back-end processes are intermingled with objects that are intended for data consumers. The back-end processes of onboarding streaming data are not something that should be visible to the data consumption community as this data is almost guaranteed to be incomplete. This is not just a matter of table and column names, but also the data itself. When users are querying the data, often the teams assembling the data sets do not simplify the data enough to be informational.
One of the big signs this has occurred is end-users constantly having to reconcile data duplication issues. These issues consistently tie back to #1 (Configuring Access Controls Tactical) with organizations not understanding how to segregate the community to ensure the objects can be consistently shared.
 Duplication of Data
Duplication of Data
For people that are new to Snowflake, one of the biggest shocks is that there is no such thing as primary keys to keep duplicates from occurring. This, however, is also the reason that Snowflake is SO much faster and more scalable. But, this means there is nothing that stops a customer from loading the same file or data multiple times. From an end-user perspective, this can create some ridiculous resulting data like one trillion dollars of annual revenue. Organizations that don’t have a plan for mitigating data duplication, and it’s downstream effects, end up with an unusable analytical environment.
Find the Hay in the Needlestack
As mentioned earlier, Snowflake has no limitation to the number of objects you can be exposed to. These objects can be secured for only certain groups, but organizations struggle to enforce those access controls as we mentioned earlier. Thus it is common for Snowflake users to be greeted with way too many objects that may or may not be used.
Untangling the Problem
Intricity has solutions to the challenges surfaced in this whitepaper. After years of deployments, Intricity has developed a formulary which it uses to automatically monitor a Snowflake deployment. This formulary benchmarks a broad spectrum of performance measures and processes then compares them to hundreds of Snowflake deployment benchmarks.
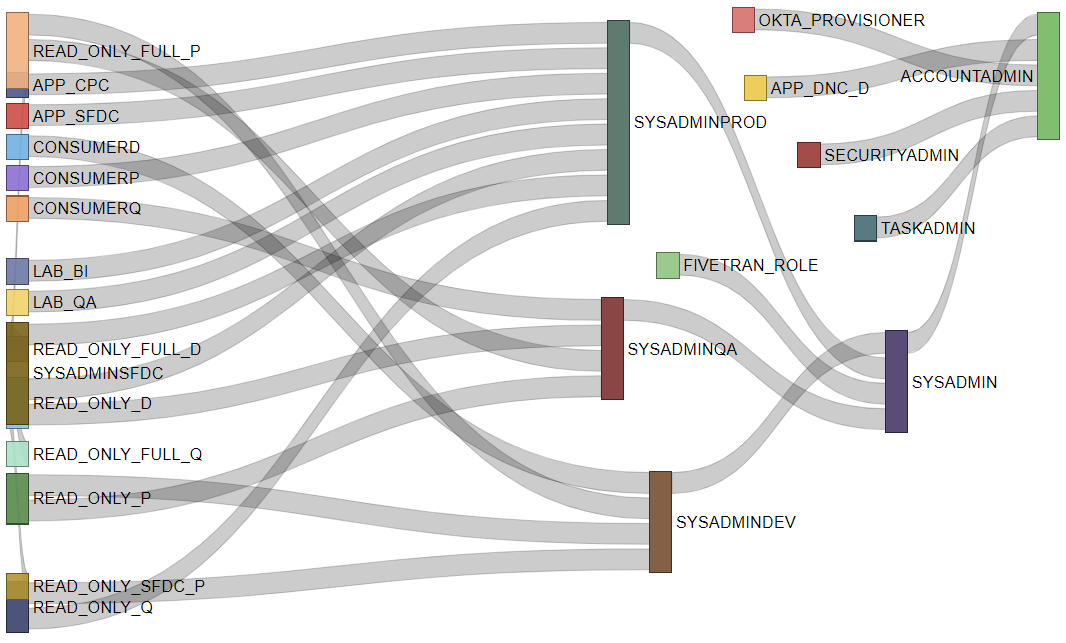
Additionally, Intricity has the ability to reveal the intertwined inheritance which is in Snowflake Roles. This deep dive into this inheritance is just the surface, as there are deeper capabilities also being deployed to simplify security for Intricity clients.
The surfacing of performance issues and the ability to address the access control challenges is something Intricity has productized in a sister company called FlowObjects. FlowObjects provides multiple tools to address common challenges for Snowflake customers, two that are salient to this whitepaper are
- Access Control Master: https://flowobjects.com/access-control-master
- Auditing and Monitoring Analytics: https://flowobjects.com/auditing-monitoring
Intricity leverages the Auditing and Monitoring solution during its Snowflake Health Checks to build a set of tactical and strategic recommendations. The persistence of critical performance metrics provides visibility into potential efficiency challenges. Those recommendations are not just best guesses but rather a deep corollary to how the organization might better interact with Snowflake's query optimizers and make structural changes. The execution of the Intricity recommendations has resulted in better Snowflake performance by an order of 5X. At the completion of the Intricity Health Check, customers are able to decide whether they wish to continue leveraging the Auditing and Monitoring solution or decommission its use after the Health Check.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
