

Written by Jared Hillam
 To get to the meat of what a Data Warehouse is, there usually are a few concepts that have to be better understood.
To get to the meat of what a Data Warehouse is, there usually are a few concepts that have to be better understood.
What it's Not
A Data Warehouse is not something you will be buying off the shelf of your local cloud vendor or software provider. While there are specialized hosting solutions for Data Warehouses, don't confuse that with the Data Warehouse itself. A Data Warehouse is a solution. Every solution stems from a problem that needs to be fixed. So what is the problem that Data Warehousing is fixing? Let's reveal that by going through a case study then piecing it apart.
Problem Statement Case Study
 A national grocer brand had built a significant market dominance in their respective locations and was seeking to double in size. The organization was already a substantial size, and one of the glaring challenges they were dealing with was the difficulty of making decisions that impacted the operation of the business. To make these decisions the organization had a horde of data analysts. These analysts worked to gather data from various sources and roll it up for their direct reports to interpret. These silos-of-analysis would ultimately roll up to executive management which were used as a basis for their decision making meetings. The challenge to executive management was that the many sources of analysis made it difficult to determine which version of the "truth" was to be believed. Each source of data seemed to give a different picture of reality. This disparity was particularly stressful when "make or break" decisions were on the table. While these challenges plagued the executive management meetings, the disparity of truth also impacted the process owners. The merchant teams were particularly impaired by this.
A national grocer brand had built a significant market dominance in their respective locations and was seeking to double in size. The organization was already a substantial size, and one of the glaring challenges they were dealing with was the difficulty of making decisions that impacted the operation of the business. To make these decisions the organization had a horde of data analysts. These analysts worked to gather data from various sources and roll it up for their direct reports to interpret. These silos-of-analysis would ultimately roll up to executive management which were used as a basis for their decision making meetings. The challenge to executive management was that the many sources of analysis made it difficult to determine which version of the "truth" was to be believed. Each source of data seemed to give a different picture of reality. This disparity was particularly stressful when "make or break" decisions were on the table. While these challenges plagued the executive management meetings, the disparity of truth also impacted the process owners. The merchant teams were particularly impaired by this.  These merchants were on the front line with their suppliers, negotiating unit pricing, and delivery methods. Their ability to successfully execute their decisions had multi-million dollar repercussions to the grocer's bottom line. However the merchants were constantly playing catch up trying to prepare analysis for negotiations with their suppliers and determining the right logistics for their products. For them to cobble together analysis, they had to manually reach into various application systems which were the source of data. These were applications like their Point of Sale (POS) system, Accounting systems, Manufacturing systems, Logistics Tracking systems, Human Resource systems, Web Traffic systems, etc. The structure of the data coming out of these systems was clearly not designed to be business friendly, but rather the structure of the data was suited to service the internal functions of the application. Additionally the actual extraction of the data from these source systems was very difficult to obtain as they couldn't interrupt the applications core function. The grocer began creating copies of application systems which users could access as to not disrupt the users of the application. The number of copies and combinations of copies began to count in the hundreds.
These merchants were on the front line with their suppliers, negotiating unit pricing, and delivery methods. Their ability to successfully execute their decisions had multi-million dollar repercussions to the grocer's bottom line. However the merchants were constantly playing catch up trying to prepare analysis for negotiations with their suppliers and determining the right logistics for their products. For them to cobble together analysis, they had to manually reach into various application systems which were the source of data. These were applications like their Point of Sale (POS) system, Accounting systems, Manufacturing systems, Logistics Tracking systems, Human Resource systems, Web Traffic systems, etc. The structure of the data coming out of these systems was clearly not designed to be business friendly, but rather the structure of the data was suited to service the internal functions of the application. Additionally the actual extraction of the data from these source systems was very difficult to obtain as they couldn't interrupt the applications core function. The grocer began creating copies of application systems which users could access as to not disrupt the users of the application. The number of copies and combinations of copies began to count in the hundreds.
The grocer needed to get out of the data collection business and into the grocery business. In other words, their day-to-day was consisting of data manipulation and munging and not progressing their core business. Ultimately this became a clear barrier in keeping the business from obtaining its goal of doubling in size.
Piecing Apart the Problem
So lets break down the different parts of the problem into smaller chunks that can be identified.
- Many Data Sources - The sources of the data are the application systems that are being used by the organization to enter orders, track purchases, etc. The many sources of data being accessed by the hundreds of employees meant that there were thousands of connections that had to be individually maintained.
- Slow queries - The structure of how Application data is stored is NOT designed for batch retrieval. Rather it's designed to be efficient at reading a single record, writing a single record, reading a single record, writing a single record, etc. So when you ask that structure (or Schema) to cough up one million records, you might as well go take the rest of the day off while the query runs.
- Complex Logic - Application data is NOT designed for human consumption, but rather it is used to pull the levers running the internal cogs of the application. Yes it does contain the data the business wants, but only after careful assembly of logic can this be revealed. This means that even "simple" queries require a massive effort to piece together.
- Decentralized Logic - The logic for each analysis lived in people's heads or was nested in individual analytics. This meant that little sharing occurred between analysts, discoveries or corrections of logic were rarely leveraged across the organization.
- Many Versions of the Truth - The natural outcome of having Decentralized Logic, is too many versions of the truth. Executive meetings on important decisions became arguments on who's version of the truth was correct.
A Data Warehouse Is...
A Data Warehouse is the culmination of a solution to solve these 5 problems, but let's get into what it physically is.
It is a Database
Yes, the Data Warehouse is a database. Before you brush it off saying, "I already have a database," let's differentiate. A generic database like Oracle or SQL Server can become whatever you want it to be. You can either use it to process and store singular transactions (OLTP) or you can have it be a Data Warehouse for corporate analytics. What differentiates one from another is it's schema.
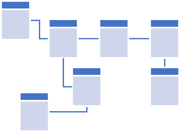 An OLTP schema typically positions the tables and their relationships in a very linear path to a singular key. This makes processing individual transactions predictable and auditable.
An OLTP schema typically positions the tables and their relationships in a very linear path to a singular key. This makes processing individual transactions predictable and auditable.
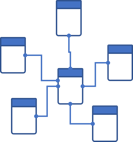 A Data Warehouse schema on the other hand repositions the tables to optimize the relationship between attributes and measurements. This is done by centralizing all the measures in a center table and all the attributes in surrounding tables. This not only makes the SQL logic for acquiring data much easier to write but it also increases the query execution speed dramatically.
A Data Warehouse schema on the other hand repositions the tables to optimize the relationship between attributes and measurements. This is done by centralizing all the measures in a center table and all the attributes in surrounding tables. This not only makes the SQL logic for acquiring data much easier to write but it also increases the query execution speed dramatically.
There are database platforms that further optimize this query speed and are built for high output on-demand like Snowflake. Coupling the engineering of a Data Warehouse on top of these specialized platforms makes for a very efficient, high-speed information delivery solution. But how does this equate to solving our 5 problems mentioned above? Well, remember that I was careful to say that it's the "culmination of a solution to solve these 5 problems". To get to the point where you have this structure in place, there's work to do. And we haven't even scratched the surface yet. So think of the Data Warehouse as one of the last destinations just before it gets consumed by the masses of dashboards, analytics, reports, and data exports. Getting to that point requires quite a bit of build up.
Arriving to that Culmination
Solving Problem #1
To ensure that we can actually keep the data refreshed, we have to solve Problem #1 (Many Data Sources). This is often called the "Locality Problem" in the Intricity 101 video series. To solve this, there needs to be a non-intrusive way of accessing records from transaction systems which are designed to service a Graphical User Interface (GUI) of an application. So tying up an application's database to cough up records is not usually an option. So how do you retrieve anything then?  The key is in parsing the database logs. Application databases can be configured to keep a detailed log of every event occurring including every record being changed or updated. There is a cottage industry of vendors that have created elaborate parsers to traverse these logs and rifle out any data updates. These solutions are called Change Data Capture (CDC) tools and they are a critical component to acquiring data off of source systems. One additional benefit of CDC tools is that they allow the data to be constantly streamed off the source application systems. These CDC solutions also address the problem of getting the data streamed into the cloud which simplifies the complexity of keeping the target data store in sync with the source systems. This takes us to the next step in solving Problem #1: centralizing the data.
The key is in parsing the database logs. Application databases can be configured to keep a detailed log of every event occurring including every record being changed or updated. There is a cottage industry of vendors that have created elaborate parsers to traverse these logs and rifle out any data updates. These solutions are called Change Data Capture (CDC) tools and they are a critical component to acquiring data off of source systems. One additional benefit of CDC tools is that they allow the data to be constantly streamed off the source application systems. These CDC solutions also address the problem of getting the data streamed into the cloud which simplifies the complexity of keeping the target data store in sync with the source systems. This takes us to the next step in solving Problem #1: centralizing the data.
The challenge with centralizing streaming data is that it's arriving in a constant stream. So a best practice is to land the data in a loose Landing Zone. This is a location that doesn't have gate keeping measures, and is entirely designed for automated processes to deal with late arriving data, and data that isn't yet organized into a pristine representation of the source. The automated processes in the Landing Zone trigger to load into a more organized layer called the Data Lake. In the Data Lake, we have whole-application data sets that appear with the same schema as we saw in the application source.  The difference being that all those application data sources are in a single Data Lake. This effectively solves the "Locality Problem" and gives the organization one place to access their data. MANY organizations make the mistake of stopping here, something that should be called "IT malpractice". Many organizations take a hands-off approach by just deploying the Data Lake. This approach leaves the hardest problems (2-5) in the lap of the Business Stakeholders. Organizations taking this approach end up with highly tribal cultures, decentralized logic, and a lot of Executive Stakeholder arguments about who's version of the truth is correct.
The difference being that all those application data sources are in a single Data Lake. This effectively solves the "Locality Problem" and gives the organization one place to access their data. MANY organizations make the mistake of stopping here, something that should be called "IT malpractice". Many organizations take a hands-off approach by just deploying the Data Lake. This approach leaves the hardest problems (2-5) in the lap of the Business Stakeholders. Organizations taking this approach end up with highly tribal cultures, decentralized logic, and a lot of Executive Stakeholder arguments about who's version of the truth is correct.
Solving Problems #2-5
The remaining problems are addressed in the Data Warehouse. And this is really where the hard work is. Every step up to this point could be done without the Business Stakeholders getting involved, but the Data Warehouse requires their express engagement. Remember our discussion about the Data Warehouse Schema? 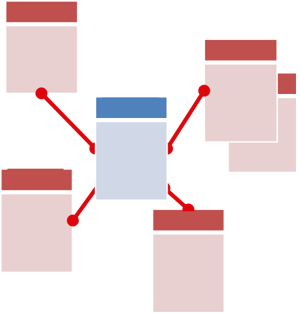 That schema is something that is directly related to the Business Stakeholder needs for information. This is the layer that simplifies the data into an information-ready framework which can be combined into N number of analytics. Thus the first step is to conduct Strategic Sessions with the Business Stakeholders from the top down to determine their information consumption needs. This top down approach ensures that the information will indeed be used once it's in place. There are several deliverables in a Data Warehouse Strategy that we won't go into in this white paper, but one of the critical ones is this conceptual Data Model.
That schema is something that is directly related to the Business Stakeholder needs for information. This is the layer that simplifies the data into an information-ready framework which can be combined into N number of analytics. Thus the first step is to conduct Strategic Sessions with the Business Stakeholders from the top down to determine their information consumption needs. This top down approach ensures that the information will indeed be used once it's in place. There are several deliverables in a Data Warehouse Strategy that we won't go into in this white paper, but one of the critical ones is this conceptual Data Model.
As this Data Model goes through further refinement, it ultimately becomes the schema of the Data Warehouse. This model, once populated with data, will represent a conformed and information-ready source of data which the organization can agree on as a "single version of the truth." Queries from this model are extremely simplistic compared to the gymnastics required to get the same information out of an application system. For example a query that took 2000 lines of SQL now just might just take 80, effectively solving #3 (Complex Logic). "But wait, how are we simplifying this logic? After all, it has to live somewhere." This takes us to the most expensive part of building a Data Warehouse: building the integration logic.
Once you have the schema designed, there is an effort required to conform the data in the Data Lake to the pristine Data Model of the Data Warehouse. Building that logic is where the effort really lies.  There are tools to assist in automating this process and certainly speed up the steps of building the integration logic. Some organizations opt to deploy their integration logic directly in code instead of investing in a mapping tool. However it's done, the logic of how those mappings are to be expressed must be established. Once this framework for moving data from the Data Lake is in place, the loading of that data becomes either a triggered or scheduled event.
There are tools to assist in automating this process and certainly speed up the steps of building the integration logic. Some organizations opt to deploy their integration logic directly in code instead of investing in a mapping tool. However it's done, the logic of how those mappings are to be expressed must be established. Once this framework for moving data from the Data Lake is in place, the loading of that data becomes either a triggered or scheduled event.
In some cases the entire Data Warehouse loads in real time. The moment the CDC trigger occurs, all the down stream triggers in the Landing Zone, Data Lake, and Integration Routines load the data.  This triggering is governed by crafty Orchestration layers. Once this integration is in place and you have data landing in your vetted Data Model, you have... a Data Warehouse.
This triggering is governed by crafty Orchestration layers. Once this integration is in place and you have data landing in your vetted Data Model, you have... a Data Warehouse.
You've solved the slow running queries (2) by persisting the records in a data model that is optimized for efficient processing. You've saved the users from having to write complex logic (3) to get information out of the data by modeling the data into an information-ready schema. You've addressed all the decentralized logic (4) by automating the process of integrating all the disparate data into a conformed set of measures and attributes in an easy to query Data Model. You've addressed the "many versions of the truth" by providing an auditable, single data source that Executive Management can sanction as their go-to for information across the organization.
So as you can see, it's not always easy for Data Warehouse Architects to carry small talk about what they do for work or to even answer such a simple question such as, "What is a Data Warehouse?"
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
