

Written by Jared Hillam

Remember the Ginsu 2000 commercials in the ‘90s? By the end of the commercial you were convinced that you couldn’t live without such a powerful cutting utensil. “But wait there’s more…!”
We’re susceptible to buzzwords and trends in the consumer market, but the business market is no exception. Remember the craze of Big Data? The buzz was so nutty that it drove Dan Ariely from Duke University to state, “Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it...”
Data Science is that buzzword today. Nobody wants to admit that they’re not doing Data Science, lest they admit that they’re “behind the times.” But herein lies the problem: in an effort to push their organization into Data Science, Business Stakeholders are ignoring the actual needs the organization has to consume data. So rather than using the tools they already have to address the problem sitting right in front of them, they jump the shark assuming better results will follow.
One example that comes to mind is an organization that we visited in Spring of 2019 in Manhattan. They were very excited to show us their Data Science project which they had rolled out. Mind you this was a mature organization which had multiple data integration and BI deployments in the past. The Business Stakeholders had caught the Data Science bug and decided to build a new team in the organization that could help deploy a new program. As we went through their deployment, one thing that became very clear is that there wasn’t really any “Science” going on. Rather what had happened was that the Data Science team stood up a competing Data Warehouse within the organization which created a data siloing problem, leading to executives being unsure of which source of truth was right. What’s more, the Data Science team wasn’t building a discovery platform but rather a data distribution platform. There was no science being done in their data science program. What the organization was left with was maintaining two competing teams supporting their own factions within the company. Interestingly enough, the organization seemed completely unaware of this mess and was more excited by the fact that they were using data science tools. After some careful solution architecture sessions from INTRICITY, the organization realized the mess that had been created.
Science VS Scale
Science
When you read an article about a breakthrough that scientists have made, do you expect it to be usable to the general public right away? I’m sure in some rare cases it happens, but usually there are huge lags before we can make those discoveries practical. Often it turns out that the assumptions were wrong or that the circumstances for the discovery only apply to a certain scenario.
As scientific ideas begin to approach the complexity of scale to the masses, the science gets the ultimate proof of value. But getting there is complex. Elon Musk underscored, “the difficulty and value of manufacturing is underappreciated." He told journalists, "It's relatively easy to make a prototype but extremely difficult to mass manufacture a vehicle reliably at scale. Even for rocket science, it's probably a factor of 10 harder to design a manufacturing system for a rocket than to design the rocket. For cars it's maybe 100 times harder to design the manufacturing system than the car itself."
One fundamental element of doing Science is a Big 5 trait called Openness, which is being open to new ideas, discoveries, and avoiding hard boundaries. This trait allows questions to be asked that traverse the walled gardens of our assumptions, corporate rulebooks, and legal red tape. Additionally, it allows us to live outside the rigid data schemas and integration routines that narrow the organizations focus to drive efficiency. This is the world that data science needs to live in to successfully craft the questions which will lead to greater efficiencies and opportunities for an organization’s future.
Scale
We spend a lot more time talking about science than we do scale. Elon Musk was right when he said, “The difficulty and value of manufacturing is underappreciated.” The task of setting up the framework for automating repetition at scale requires all the avoided assumptions and rules to come rushing back into the picture. The prototype discoveries have to square up with the reality of the existing processes, structure, rules, and technical limitations of the real world.
One fundamental element of creating Scale is a Big 5 trait called Conscientiousness, which is probably better termed as Orderliness. These are the traits of structure, timeliness, order, and predictability. Orderliness appeals to repetition because we can rely on the consistency of the results. In turn this consistency allows organizations to profit from a predictable outcome, and further tune that outcome to maximize the profits. This is the world that data integration and data warehousing lives in. Applying schema and logic to raw data is what can successfully scale information delivery to 100s or even 1000s of users. I’ll call this Information at Scale.
Probabilistic vs Deterministic
For years I’ve been trying to draw a parallel description for how to explain the Science vs Scale concept in more concrete terms, terms that could be used as a grey line of demarcation between the two disciplines. While listening to a podcast the terms “Probabilistic vs Deterministic” came up, I quickly wrote it down. That was the term which could provide enough of a delineation between Data Science and Information at Scale.
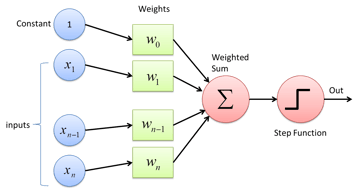
Due to the experimental nature of Data Science and the need to test unseen factors, we often live in the world of probabilities. Even at the core of machine learning is a bunch of little weighted probabilities firing that spit out results.
So the question we can ask ourselves from a project perspective is, “What kind of work am I doing on the data?” If the nature of the project is highly probabilistic it probably should live in the realm of your data science team.
On the other hand if we are deterministically conforming data attributes so they can be expressed in a reusable data schema, then we should be leveraging our data integration team.
Mixing and Mingling
So how do we mix and mingle the strengths of both teams to maximize their contribution to an organization? One point of “scale” that Data Science teams need is reliable access to corporate data sources. The Data Integration teams can play a central role in ensuring that the Data-to-Information process includes a landing zone which supports the Data Science activities. In a solution architecture this usually expresses itself in a Data Lake. This provides a place for Data Science teams to take advantage of the freedom to explore raw data feeds from the corporate data sources, and ensures low barriers of entry for adding new data.
Drawing from the Data Lake is a data integration and conformity layer which ultimately becomes the Data Warehouse. This data warehouse acts as a location where the agreed logic for how data is to be perceived can be fully described. Additionally it acts as a location which the whole business can call the “best version of the truth.” While the purpose of the data warehouse is to feed the broad business community, it doesn’t exclude the data scientists. Indeed the Data Warehouse can save Data Science teams 1000s of hours of repetitive data munging out of the Data Lake to make discoveries.
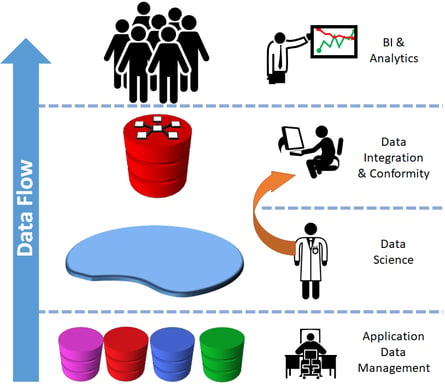
As data science teams uncover discoveries regarding the business and its processes, these discoveries enter a vetting and promotion process so their data can be leveraged with the existing data warehouse. This ensures that discoveries are incorporated into the “manufacturing process” of turning data into information for the business and they don’t develop separate silos that will confuse the business.

The goal is to strike a balance between openness and orderliness. Both are important components in any organization. When openness overrules orderliness we end up with chaos. When orderliness overrules openness, organizations become unaware of their potential and threats.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
