

Written by Jared Hillam
About Client
The Client is a leader in transaction data analytics for the Financial Services industry. They house many critical analytics for large-scale fortune organizations to analyze ACH transactions, retail banking customer demographics, consumer behaviors, and a host of other critical analytics.
Challenge
One of the offerings provided by the Client required the matching of credit card transactions to identify unique vendors like Taco Bell, Amazon, etc. This unique information was highly valuable to many analytics and to their Financial Services clients.
The data sets being acquired on behalf of the Client's Financial Services customers was not only large in its own right (4 billion records) as it spanned multiple Financial Services Institutions, but also had daily streams of 12 million additional records.
Navigating Constraints
The Client had been using Snowflake as their enterprise standard, but this particular need to narrow unique vendor records from credit cards had them looking at other compute solutions as brute force machine learning appeared to be the only legitimate way forward.
Training machine learning models on identity resolution for a specific organization’s data requires a much more efficient method of training. The compute cost of training such a massive data set to do brute force compares would take weeks of extensive compute costs to generate models. This is because a brute force comparison requires string comparisons with the following counts
number of records * (number of records -1)/2
4,000,000,000 * (4,000,000,000-14,)/2 =
7,999,999,998,000,000,000 comparisons
That's nearly 8 quintillion comparisons! Therefore, the problem required out-of-the-box thinking. The cost of brute force generation of a machine learning model from scratch would have required them to potentially change platforms and the compute costs would have been astronomical.
Win 1:
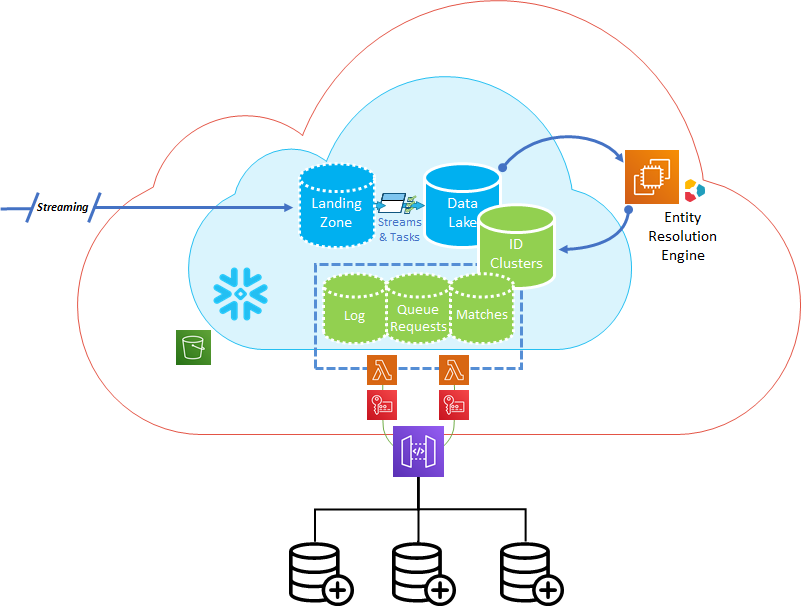
Intricity architected an Identity Resolution solution that avoided the onboarding of a completely separate compute engine for machine learning. The solution coupled supervised regression model and string comparison algorithms to efficiently generate unique record identities.
Win 2:
To optimize the efficiency of the training, Intricity created a cleansing step that standardized the record formats. In turn, the noise was eliminated from the string comparisons which greatly cut down on compute cycles to map appropriate string algorithms.
Win 3:
Intricity implemented its Identity Management powered by Snowflake. The solution is a supervised regression modeling system that allowed the client team members to compare presented matches and indicate which records were not matches. The presentation of potential matches and the human "teaching" of what should be excluded trained the regression model. The regression model in turn allocated about 30 different string comparison algorithms (predicates) that produced the best match to the data set.
This allows for the nuance of appropriate string comparison algorithms to be applied. The reduced cost of Entity Resolution was tremendous as all the applied algorithmic predicates were natively written in Snowflake and the ML could assign them appropriately.
Win 4:
Intricity created canopies and groups which enabled the nearly 8 quintillion comparisons to be broken down into more logical sets. These represent segments that are likely to contain matches, like the same country. This breaks down the transaction records into sets that are a lot more computable at scale without brute-forcing the comparisons from scratch.
Win 5:
The customer gained a Unique Vendor data set derived from billions of credit card transactions. The unique vendors can be used for a host of products offered to the Client's Financial Services customers including several productized analytics solutions and cleansing offerings.
Who is Intricity?
Intricity is a specialized selection of over 100 Data Management Professionals, with offices located across the USA and Headquarters in New York City. Our team of experts has implemented in a variety of Industries including, Healthcare, Insurance, Manufacturing, Financial Services, Media, Pharmaceutical, Retail, and others. Intricity is uniquely positioned as a partner to the business that deeply understands what makes the data tick. This joint knowledge and acumen has positioned Intricity to beat out its Big 4 competitors time and time again. Intricity’s area of expertise spans the entirety of the information lifecycle. This means when you’re problem involves data; Intricity will be a trusted partner. Intricity's services cover a broad range of data-to-information engineering needs:

What Makes Intricity Different?
While Intricity conducts highly intricate and complex data management projects, Intricity is first a foremost a Business User Centric consulting company. Our internal slogan is to Simplify Complexity. This means that we take complex data management challenges and not only make them understandable to the business but also make them easier to operate. Intricity does this through using tools and techniques that are familiar to business people but adapted for IT content.
Thought Leadership
Intricity authors a highly sought after Data Management Video Series targeted towards Business Stakeholders at https://www.intricity.com/videos. These videos are used in universities across the world. Here is a small set of universities leveraging Intricity’s videos as a teaching tool:

Talk With a Specialist
If you would like to talk with an Intricity Specialist about your particular scenario, don’t hesitate to reach out to us. You can write us an email: specialist@intricity.com
(C) 2023 by Intricity, LLC
This content is the sole property of Intricity LLC. No reproduction can be made without Intricity's explicit consent.
Intricity, LLC. 244 Fifth Avenue Suite 2026 New York, NY 10001
Phone: 212.461.1100 • Fax: 212.461.1110 • Website: www.intricity.com
